THE FOURTH QUADRANT: A MAP OF THE LIMITS OF STATISTICS [1]
THE FOURTH QUADRANT: A MAP OF THE LIMITS OF STATISTICS
Statistical and applied probabilistic knowledge is the core of knowledge; statistics is what tells you if something is true, false, or merely anecdotal; it is the "logic of science"; it is the instrument of risk-taking; it is the applied tools of epistemology; you can't be a modern intellectual and not think probabilistically—but... let's not be suckers. The problem is much more complicated than it seems to the casual, mechanistic user who picked it up in graduate school. Statistics can fool you. In fact it is fooling your government right now. It can even bankrupt the system (let's face it: use of probabilistic methods for the estimation of risks did just blow up the banking system).
The current subprime crisis has been doing wonders for the reception of any ideas about probability-driven claims in science, particularly in social science, economics, and "econometrics" (quantitative economics). Clearly, with current International Monetary Fund estimates of the costs of the 2007-2008 subprime crisis, the banking system seems to have lost more on risk taking (from the failures of quantitative risk management) than every penny banksever earned taking risks. But it was easy to see from the past that the pilot did not have the qualifications to fly the plane and was using the wrong navigation tools: The same happened in 1983 with money center banks losing cumulatively every penny ever made, and in 1991-1992 when the Savings and Loans industry became history.
It appears that financial institutions earn money on transactions (say fees on your mother-in-law's checking account) and lose everything taking risks they don't understand. I want this to stop, and stop now— the current patching by the banking establishment worldwide is akin to using the same doctor to cure the patient when the doctor has a track record of systematically killing them. And this is not limited to banking—I generalize to an entire class of random variables that do not have the structure we thing they have, in which we can be suckers.
And we are beyond suckers: not only, for socio-economic and other nonlinear, complicated variables, we are riding in a bus driven a blindfolded driver, but we refuse to acknowledge it in spite of the evidence, which to me is a pathological problem with academia. After 1998, when a "Nobel-crowned" collection of people (and the crème de la crème of the financial economics establishment) blew up Long Term Capital Management, a hedge fund, because the "scientific" methods they used misestimated the role of the rare event, such methodologies and such claims on understanding risks of rare events should have been discredited. Yet the Fed helped their bailout andexposure to rare events (and model error) patently increased exponentially (as we can see from banks' swelling portfolios of derivatives that we do not understand).
Are we using models of uncertainty to produce certainties?
This masquerade does not seem to come from statisticians—but from the commoditized, "me-too" users of the products. Professional statisticians can be remarkably introspective and self-critical. Recently, the American Statistical Association had a special panel session on the "black swan" concept at the annual Joint Statistical Meeting in Denver last August. They insistently made a distinction between the "statisticians" (those who deal with the subject itself and design the tools and methods) and those in other fields who pick up statistical tools from textbooks without really understanding them. For them it is a problem with statistical education and half-baked expertise. Alas, this category of blind users includes regulators and risk managers, whom I accuse of creating more risk than they reduce.
So the good news is that we can identify where the danger zone is located, which I call "the fourth quadrant", and show it on a map with more or less clear boundaries. A map is a useful thing because you know where you are safe and where your knowledge is questionable. So I drew for the Edge [2]readers a tableau showing the boundaries where statistics works well and where it is questionable or unreliable. Now once you identify where the danger zone is, where your knowledge is no longer valid, you can easily make some policy rules: how to conduct yourself in that fourth quadrant; what to avoid.
So the principal value of the map is that it allows for policy making. Indeed, I am moving on: my new project is about methods on how to domesticate the unknown, exploit randomness, figure out how to live in a world we don't understand very well. While most human thought (particularly since the enlightenment) has focused us on how to turn knowledge into decisions, my new mission is to build methods to turn lack of information, lack of understanding, and lack of "knowledge" into decisions—how, as we will see, not to be a "turkey".
This piece has a technical appendix that presents mathematical points and empirical evidence. (See link below.) It includes a battery of tests showing that no known conventional tool can allow us to make precise statistical claims in the Fourth Quadrant. While in the past I limited myself to citing research papers, and evidence compiled by others (a less risky trade), here I got hold of more than 20 million pieces of data (includes 98% of the corresponding macroeconomics values of transacted daily, weekly, and monthly variables for the last 40 years) and redid a systematic analysis that includes recent years.
What Is Fundamentally Different About Real Life
My anger with "empirical" claims in risk management does not come from research. It comes from spending twenty tense (but entertaining) years taking risky decisions in the real world managing portfolios of complex derivatives, with payoffs that depend on higher order statistical properties —and you quickly realize that a certain class of relationships that "look good" in research papers almost never replicate in real life (in spite of the papers making some claims with a "p" close to infallible). But that is not the main problem with research.
For us the world is vastly simpler in some sense than the academy, vastly more complicated in another. So the central lesson from decision-making (as opposed to working with data on a computer or bickering about logical constructions) is the following: it is the exposure (or payoff) that creates the complexity —and the opportunities and dangers— not so much the knowledge ( i.e., statistical distribution, model representation, etc.). In some situations, you can be extremely wrong and be fine, in others you can be slightly wrong and explode. If you are leveraged, errors blow you up; if you are not, you can enjoy life.
So knowledge (i.e., if some statement is "true" or "false") matters little, very little in many situations. In the real world, there are very few situations where what you do and your belief if some statement is true or false naively map into each other. Some decisions require vastly more caution than others—or highly more drastic confidence intervals. For instance you do not "need evidence" that the water is poisonous to not drink from it. You do not need "evidence" that a gun is loaded to avoid playing Russian roulette, or evidence that a thief a on the lookout to lock your door. You need evidence of safety—not evidence of lack of safety— a central asymmetry that affects us with rare events. This asymmetry in skepticism makes it easy to draw a map of danger spots.
The Dangers Of Bogus Math
I start with my old crusade against "quants" (people like me who do mathematical work in finance), economists, and bank risk managers, my prime perpetrators of iatrogenic risks (the healer killing the patient). Why iatrogenic risks? Because, not only have economists been unable to prove that their models work, but no one managed to prove that the use of a model that does not work is neutral, that it does not increase blind risk taking, hence the accumulation of hidden risks.
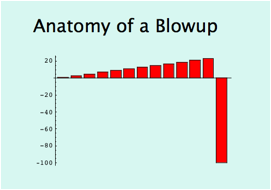
Figure 1 My classical metaphor: A Turkey is fed for a 1000 days—every days confirms to its statistical department that the human race cares about its welfare "with increased statistical significance". On the 1001st day, the turkey has a surprise.

Figure 2 The graph above shows the fate of close to 1000 financial institutions (includes busts such as FNMA, Bear Stearns, Northern Rock, Lehman Brothers, etc.). The banking system (betting AGAINST rare events) just lost > 1 Trillion dollars (so far) on a single error, more than was ever earned in the history of banking. Yet bankers kept their previous bonuses and it looks like citizens have to foot the bills. And one Professor Ben Bernanke pronounced right before the blowup that we live in an era of stability and "great moderation" (he is now piloting a plane and we all are passengers on it).
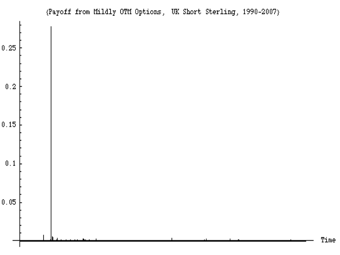
Figures 1 and 2 show you the classical problem of the turkey making statements on the risks based on past history (mixed with some theorizing that happens to narrate well with the data). A friend of mine was sold a package of subprime loans (leveraged) on grounds that "30 years of history show that the trade is safe." He found the argument unassailable "empirically". And the unusual dominance of the rare event shown in Figure 3 is not unique: it affects all macroeconomic data—if you look long enough almost all the contribution in some classes of variables will come from rare events (I looked in the appendix at 98% of trade-weighted data).Figure 3 The graph shows the daily variations a derivatives portfolio exposed to U.K. interest rates between 1988 and 2008. Close to 99% of the variations, over the span of 20 years, will be represented in 1 single day—the day the European Monetary System collapsed. As I show in the appendix, this is typical with ANY socio-economic variable (commodity prices, currencies, inflation numbers, GDP, company performance, etc. ). No known econometric statistical method can capture the probability of the event with any remotely acceptable accuracy (except, of course, in hindsight, and "on paper"). Also note that this applies to surges on electricity grids and all manner of modern-day phenomena.
Now let me tell you what worries me. Imagine that the Turkey can be the most powerful man in world economics, managing our economic fates. How? A then-Princeton economist called Ben Bernanke made a pronouncement in late 2004 about the "new moderation" in economic life: the world getting more and more stable—before becoming the Chairman of the Federal Reserve. Yet the system was getting riskier and riskier as we were turkey-style sitting on more and more barrels of dynamite—and Prof. Bernanke's predecessor the former Federal Reserve Chairman Alan Greenspan was systematically increasing the hidden risks in the system, making us all more vulnerable to blowups.
By the "narrative fallacy" the turkey economics department will always manage to state, before thanksgivings that "we are in a new era of safety", and back-it up with thorough and "rigorous" analysis. And Professor Bernanke indeed found plenty of economic explanations—what I call the narrative fallacy—with graphs, jargon, curves, the kind of facade-of-knowledge that you find in economics textbooks. (This is the find of glib, snake-oil facade of knowledge—even more dangerous because of the mathematics—that made me, before accepting the new position in NYU's engineering department, verify that there was not a single economist in the building. I have nothing against economists: you should let them entertain each others with their theories and elegant mathematics, and help keep college students inside buildings. But beware: they can be plain wrong, yet frame things in a way to make you feel stupid arguing with them. So make sure you do not give any of them risk-management responsibilities.)
Bottom Line: The Map
Things are made simple by the following. There are two distinct types of decisions, and two distinct classes of randomness.
Decisions: The first type of decisions is simple, "binary", i.e. you just care if something is true or false. Very true or very false does not matter. Someone is either pregnant or not pregnant. A statement is "true" or "false" with some confidence interval. (I call these M0 as, more technically, they depend on the zeroth moment, namely just on probability of events, and not their magnitude —you just care about "raw" probability). A biological experiment in the laboratory or a bet with a friend about the outcome of a soccer game belong to this category.
The second type of decisions is more complex. You do not just care of the frequency—but of the impact as well, or, even more complex, some function of the impact. So there is another layer of uncertainty of impact. (I call these M1+, as they depend on higher moments of the distribution). When you invest you do not care how many times you make or lose, you care about the expectation: how many times you make or lose times the amount made or lost.
Probability structures: There are two classes of probability domains—very distinct qualitatively and quantitatively. The first, thin-tailed: Mediocristan", the second, thick tailed Extremistan. Before I get into the details, take the literary distinction as follows:
In Mediocristan, exceptions occur but don't carry large consequences. Add the heaviest person on the planet to a sample of 1000. The total weight would barely change. In Extremistan, exceptions can be everything (they will eventually, in time, represent everything). Add Bill Gates to your sample: the wealth will jump by a factor of >100,000. So, in Mediocristan, large deviations occur but they are not consequential—unlike Extremistan.
Mediocristan corresponds to "random walk" style randomness that you tend to find in regular textbooks (and in popular books on randomness). Extremistan corresponds to a "random jump" one. The first kind I can call "Gaussian-Poisson", the second "fractal" or Mandelbrotian (after the works of the great Benoit Mandelbrot linking it to the geometry of nature). But note here an epistemological question: there is a category of "I don't know" that I also bundle in Extremistan for the sake of decision making—simply because I don't know much about the probabilistic structure or the role of large events.
The Map
Now it lets see where the traps are:
First Quadrant: Simple binary decisions, in Mediocristan: Statistics does wonders. These situations are, unfortunately, more common in academia, laboratories, and games than real life—what I call the "ludic fallacy". In other words, these are the situations in casinos, games, dice, and we tend to study them because we are successful in modeling them.
Second Quadrant: Simple decisions, in Extremistan: some well known problem studied in the literature. Except of course that there are not many simple decisions in Extremistan.
Third Quadrant: Complex decisions in Mediocristan: Statistical methods work surprisingly well.
Fourth Quadrant: Complex decisions in Extremistan: Welcome to the Black Swan domain. Here is where your limits are. Do not base your decisions on statistically based claims. Or, alternatively, try to move your exposure type to make it third-quadrant style ("clipping tails").

The four quadrants. The South-East area (in orange) is where statistics and models fail us.
Tableau Of Payoffs

Two Difficulties
Let me refine the analysis. The passage from theory to the real world presents two distinct difficulties: "inverse problems" and "pre-asymptotics".
Inverse Problems. It is the greatest epistemological difficulty I know. In real life we do not observe probability distributions (not even in Soviet Russia, not even the French government). We just observe events. So we do not know the statistical properties—until, of course, after the fact. Given a set of observations, plenty of statistical distributions can correspond to the exact same realizations—each would extrapolate differently outside the set of events on which it was derived. The inverse problem is more acute when more theories, more distributions can fit a set a data.
This inverse problem is compounded by the small sample properties of rare events as these will be naturally rare in a past sample. It is also acute in the presence of nonlinearities as the families of possible models/parametrization explode in numbers.
Pre-asymptotics. Theories are, of course, bad, but they can be worse in some situations when they were derived in idealized situations, the asymptote, but are used outside the asymptote (its limit, say infinity or the infinitesimal). Some asymptotic properties do work well preasymptotically (Mediocristan), which is why casinos do well, but others do not, particularly when it comes to Extremistan.
Most statistical education is based on these asymptotic, Platonic properties—yet we live in the real world that rarely resembles the asymptote. Furthermore, this compounds the ludic fallacy: most of what students of statistics do is assume a structure, typically with a known probability. Yet the problem we have is not so much making computations once you know the probabilities, but finding the true distribution.
The Inverse Problem Of The Rare Events
Let us start with the inverse problem of rare events and proceed with a simple, nonmathematical argument. In August 2007, The Wall Street Journal published a statement by one financial economist, expressing his surprise that financial markets experienced a string of events that "would happen once in 10,000 years". A portrait of the gentleman accompanying the article revealed that he was considerably younger than 10,000 years; it is therefore fair to assume that he was not drawing his inference from his own empirical experience (and not from history at large), but from some theoretical model that produces the risk of rare events, or what he perceived to be rare events.
Alas, the rarer the event, the more theory you need (since we don't observe it). So the rarer the event, the worse its inverse problem. And theories are fragile (just think of Doctor Bernanke).
The tragedy is as follows. Suppose that you are deriving probabilities of future occurrences from the data, assuming (generously) that the past is representative of the future. Now, say that you estimate that an event happens every 1,000 days. You will need a lot more data than 1,000 days to ascertain its frequency, say 3,000 days. Now, what if the event happens once every 5,000 days? The estimation of this probability requires some larger number, 15,000 or more. The smaller the probability, the more observations you need, and the greater the estimation error for a set number of observations. Therefore, to estimate a rare event you need a sample that is larger and larger in inverse proportion to the occurrence of the event.
If small probability events carry large impacts, and (at the same time) these small probability events are more difficult to compute from past data itself, then: our empirical knowledge about the potential contribution—or role—of rare events (probability × consequence) is inversely proportional to their impact. This is why we should worry in the fourth quadrant!
For rare events, the confirmation bias (the tendency, Bernanke-style, of finding samples that confirm your opinion, not those that disconfirm it) is very costly and very distorting. Why? Most of histories of Black Swan prone events is going to be Black Swan free! Most samples will not reveal the black swans—except after if you are hit with them, in which case you will not be in a position to discuss them. Indeed I show with 40 years of data that past Black Swans do not predict future Black Swans in socio-economic life.
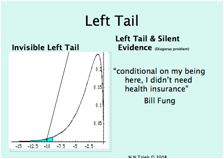
Figure 4 The Confirmation Bias At Work. For left-tailed fat-tailed distributions, we do not see much of negative outcomes for surviving entities AND we have a small sample in the left tail. This is why we tend to see a better past for a certain class of time series than warranted.
Fallacy Of The Single Event Probability
Let us look at events in Mediocristan. In a developed country a newborn female is expected to die at around 79, according to insurance tables. When she reaches her 79th birthday, her life expectancy, assuming that she is in typical health, is another 10 years. At the age of 90, she should have another 4.7 years to go. So if you are told that a person is older than 100, you can estimate that he is 102.5 and conditional on the person being older than 140 you can estimate that he is 140 plus a few minutes. The conditional expectation of additional life drops as a person gets older.
In Extremistan things work differently and the conditional expectation of an increase in a random variable does not drop as the variable gets larger. In the real world, say with stock returns (and all economic variable), conditional on a loss being worse than the 5 units, to use a conventional unit of measure units, it will be around 8 units. Conditional that a move is more than 50 STD it should be around 80 units, and if we go all the way until the sample is depleted, the average move worse than 100 units is 250 units! This extends all the way to areas in which we have sufficient sample.
This tells us that there is "no typical" failure and "no typical" success. You may be able to predict the occurrence of a war, but you will not be able to gauge its effect! Conditional on a war killing more than 5 million people, it should kill around 10 (or more). Conditional on it killing more than 500 million, it would kill a billion (or more, we don't know). You may correctly predict a skilled person getting "rich", but he can make a million, ten million, a billion, ten billion—there is no typical number. We have data, for instance, for predictions of drug sales, conditional on getting things right. Sales estimates are totally uncorrelated to actual sales—some drugs that were correctly predicted to be successful had their sales underestimated by up to 22 times!
This absence of "typical" event in Extremistan is what makes prediction markets ludicrous, as they make events look binary. "A war" is meaningless: you need to estimate its damage—and no damage is typical. Many predicted that the First War would occur—but nobody predicted its magnitude. Of the reasons economics does not work is that the literature is almost completely blind to the point.
A Simple Proof Of Unpredictability In The Fourth Quadrant
I show elsewhere that if you don't know what a "typical" event is, fractal power laws are the most effective way to discuss the extremes mathematically. It does not mean that the real world generator is actually a power law—it means you don't understand the structure of the external events it delivers and need a tool of analysis so you do not become a turkey. Also, fractals simplify the mathematical discussions because all you need is play with one parameter (I call it "alpha") and it increases or decreases the role of the rare event in the total properties.
For instance, you move alpha from 2.3 to 2 in the publishing business, and the sales of books in excess of 1 million copies triple! Before meeting Benoit Mandelbrot, I used to play with combinations of scenarios with series of probabilities and series of payoffs filling spreadsheets with clumsy simulations; learning to use fractals made such analyses immediate. Now all I do is change the alpha and see what's going on.
Now the problem: Parametrizing a power law lends itself to monstrous estimation errors (I said that heavy tails have horrible inverse problems). Small changes in the "alpha" main parameter used by power laws leads to monstrously large effects in the tails. Monstrous.
And we don't observe the "alpha. Figure 5 shows more than 40 thousand computations of the tail exponent "alpha" from different samples of different economic variables (data for which it is impossible to refute fractal power laws). We clearly have problems figuring it what the "alpha" is: our results are marred with errors. Clearly the mean absolute error is in excess of 1 (i.e. between alpha=2 and alpha=3). Numerous papers in econophysics found an "average" alpha between 2 and 3—but if you process the >20 million pieces of data analyzed in the literature, you find that the variations between single variables are extremely significant.

Figure 5—Estimation error in "alpha" from 40 thousand economic variables. I thank Pallop Angsupun for data.
Now this mean error has massive consequences. Figure 6 shows the effect: the expected value of your losses in excess of a certain amount(called "shortfall") is multiplied by >10 from a small change in the "alpha" that is less than its mean error! These are the losses banks were talking about with confident precision!

Figure 6—The value of the expected shortfall (expected losses in excess of a certain threshold) in response to changes in tail exponent "alpha". We can see it explode by an order of magnitude.
What if the distribution is not a power law? This is a question I used to get once a day. Let me repeat it: my argument would not change—it would take longer to phrase it.
Many researchers, such as Philip Tetlock, have looked into the incapacity of social scientists in forecasting (economists, political scientists). It is thus evident that while the forecasters might be just "empty suits", the forecast errors are dominated by rare events, and we are limited in our ability to track them. The "wisdom of crowds" might work in the first three quadrant; but it certainly fails (and has failed) in the fourth.
Living In The Fourth Quadrant
Beware the Charlatan. When I was a quant-trader in complex derivatives, people mistaking my profession used to ask me for "stock tips" which put me in a state of rage: a charlatan is someone likely (statistically) to give you positive advice, of the "how to" variety.
Go to a bookstore, and look at the business shelves: you will find plenty of books telling you how to make your first million, or your first quarter-billion, etc. You will not be likely to find a book on "how I failed in business and in life"—though the second type of advice is vastly more informational, and typically less charlatanic. Indeed, the only popular such finance book I found that was not quacky in nature—on how someone lost his fortune—was both self-published and out of print. Even in academia, there is little room for promotion by publishing negative results—though these, are vastly informational and less marred with statistical biases of the kind we call data snooping. So all I am saying is "what is it that we don't know", and my advice is what to avoid, no more.
You can live longer if you avoid death, get better if you avoid bankruptcy, and become prosperous if you avoid blowups in the fourth quadrant.
Now you would think that people would buy my arguments about lack of knowledge and accept unpredictability. But many kept asking me "now that you say that our measures are wrong, do you have anything better?"
I used to give the same mathematical finance lectures for both graduate students and practitioners before giving up on academic students and grade-seekers. Students cannot understand the value of "this is what we don't know"—they think it is not information, that they are learning nothing. Practitioners on the other hand value it immensely. Likewise with statisticians: I never had a disagreement with statisticians (who build the field)—only with users of statistical methods.
Spyros Makridakis and I are editors of a special issue of a decision science journal, The International Journal of Forecasting. The issue is about "What to do in an environment of low predictability". We received tons of papers, but guess what? Very few addressed the point: they mostly focused on showing us that they predict better (on paper). This convinced me to engage in my new project: "how to live in a world we don't understand".
So for now I can produce phronetic rules (in the Aristotelian sense ofphronesis, decision-making wisdom). Here are a few, to conclude.
Phronetic Rules: What Is Wise To Do (Or Not Do) In The Fourth Quadrant
1) Avoid Optimization, Learn to Love Redundancy. Psychologists tell us that getting rich does not bring happiness—if you spend it. But if you hide it under the mattress, you are less vulnerable to a black swan. Only fools (such as Banks) optimize, not realizing that a simple model error can blow through their capital (as it just did). In one day in August 2007, Goldman Sachs experienced 24 x the average daily transaction volume—would 29 times have blown up the system? The only weak point I know of financial markets is their ability to drive people & companies to "efficiency" (to please a stock analyst’s earnings target) against risks of extreme events.
Indeed some systems tend to optimize—therefore become more fragile. Electricity grids for example optimize to the point of not coping with unexpected surges—Albert-Lazlo Barabasi warned us of the possibility of a NYC blackout like the one we had in August 2003. Quite prophetic, the fellow. Yet energy supply kept getting more and more efficient since. Commodity prices can double on a short burst in demand (oil, copper, wheat) —we no longer have any slack. Almost everyone who talks about "flat earth" does not realize that it is overoptimized to the point of maximal vulnerability.
Biological systems—those that survived millions of years—include huge redundancies. Just consider why we like sexual encounters (so redundant to do it so often!). Historically populations tended to produced around 4-12 children to get to the historical average of ~2 survivors to adulthood.
Option-theoretic analysis: redundancy is like long an option. You certainly pay for it, but it may be necessary for survival.
2) Avoid prediction of remote payoffs—though not necessarily ordinary ones. Payoffs from remote parts of the distribution are more difficult to predict than closer parts.
A general principle is that, while in the first three quadrants you can use the best model you can find, this is dangerous in the fourth quadrant: no model should be better than just any model.
3) Beware the "atypicality" of remote events. There is a sucker's method called "scenario analysis" and "stress testing"—usually based on the past (or some "make sense" theory). Yet I show in the appendix how past shortfalls that do not predict subsequent shortfalls. Likewise, "prediction markets" are for fools. They might work for a binary election, but not in the Fourth Quadrant. Recall the very definition of events is complicated: success might mean one million in the bank ...or five billions!
4) Time. It takes much, much longer for a times series in the Fourth Quadrant to reveal its property. At the worst, we don't know how long. Yet compensation for bank executives is done on a short term window, causing a mismatch between observation window and necessary window. They get rich in spite of negative returns. But we can have a pretty clear idea if the "Black Swan" can hit on the left (losses) or on the right (profits).
The point can be used in climatic analysis. Things that have worked for a long time are preferable—they are more likely to have reached their ergodic states.
5) Beware Moral Hazard. Is optimal to make series of bonuses betting on hidden risks in the Fourth Quadrant, then blow up and write a thank you letter. Fannie Mae and Freddie Mac's Chairmen will in all likelihood keep their previous bonuses (as in all previous cases) and even get close to 15 million of severance pay each.
6) Metrics. Conventional metrics based on type 1 randomness don't work. Words like "standard deviation" are not stable and does not measure anything in the Fourth Quadrant. So does "linear regression" (the errors are in the fourth quadrant), "Sharpe ratio", Markowitz optimal portfolio, ANOVA shmnamova, Least square, etc. Literally anything mechanistically pulled out of a statistical textbook.
My problem is that people can both accept the role of rare events, agree with me, and still use these metrics, which is leading me to test if this is a psychological disorder.
The technical appendix shows why these metrics fail: they are based on "variance"/"standard deviation" and terms invented years ago when we had no computers. One way I can prove that anything linked to standard deviation is a facade of knowledge: There is a measure called Kurtosis that indicates departure from "Normality". It is very, very unstable and marred with huge sampling error: 70-90% of the Kurtosis in Oil, SP500, Silver, UK interest rates, Nikkei, US deposit rates, sugar, and the dollar/yet currency rate come from 1 day in the past 40 years, reminiscent of figure 3. This means that no sample will ever deliver the true variance. It also tells us anyone using "variance" or "standard deviation" (or worse making models that make us take decisions based on it) in the fourth quadrant is incompetent.
7) Where is the skewness? Clearly the Fourth Quadrant can present left or right skewness. If we suspect right-skewness, the true mean is more likely to be underestimated by measurement of past realizations, and the total potential is likewise poorly gauged. A biotech company (usually) faces positive uncertainty, a bank faces almost exclusively negative shocks. I call that in my new project "concave" or "convex" to model error.

8) Do not confuse absence of volatility with absence of risks. Recall how conventional metrics of using volatility as an indicator of stability has fooled Bernanke—as well as the banking system.
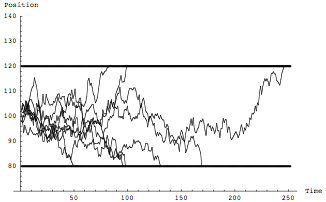
Figure 7 Random Walk—Characterized by volatility. You only find these in textbooks and in essays on probability by people who have never really taken decisions under uncertainty.
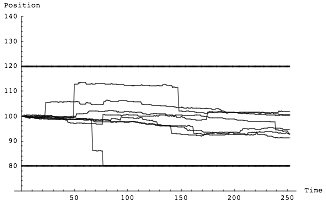
Figure 8 Random Jump process—It is not characterized by its volatility. Its exits the 80-120 range much less often, but its extremes are far more severe. Please tell Bernanke if you have the chance to meet him.
9) Beware presentations of risk numbers. Not only we have mathematical problems, but risk perception is subjected to framing issues that are acute in the Fourth Quadrant. Dan Goldstein and I are running a program of experiments in the psychology of uncertainty and finding that the perception of rare events is subjected to severe framing distortions: people are aggressive with risks that hit them "once every thirty years" but not if they are told that the risk happens with a "3% a year" occurrence. Furthermore it appears that risk representations are not neutral: they cause risk taking even when they are known to be unreliable.
Technical Appendix to "The Fourth Quadrant"—Click Here [3]