

When IARPA originally launched this project, they thought that beating the unweighted average of the crowd by 20 percent would be an ambitious goal in year one, 30 percent in year two, 40 percent in year three, and 50 percent in year four. The Good Judgment Project, for reasons that are interesting, was able to beat IARPA's fourth year benchmark in the first year and in all subsequent years. For reasons that are also maybe a little less interesting, other teams were not. I say the reasons are less interesting, I don’t think it was due to them not having the right research expertise. There were issues of mismanagement, of how they went about it. We had a way better project manager.
Putting that to the side, the Good Judgment Project was able to do far better than IARPA or any of the other researchers who were consulted on the design of the project thought possible. We were able to knock out some pretty formidable competitors. Slide twenty-nine tells you what the four big drivers of performance were in the tournament: Getting the right people on the bus, the benefits of interaction, the benefits of training, and the benefits of that strange algorithm that I call the “extremizing algorithm.”

Because of the earlier work I did on expert political judgment, we had a bit of a reputational advantage, so we did get better forecasters. That was advantage A. That wasn’t the biggest factor though. We put them together in teams and we gave those teams guidance on how to interact. We gave them training in precision questioning, we gave them training in what Andy Grove famously called “constructive confrontation”—how to disagree without being disagreeable. We gave them some guidance on how to do those sorts of things.
Interestingly, the teams in the prediction markets were, for the most part, running close to parity. The superforecaster teams, of course, were doing much better. It turns out that collaborating in teams and competing in prediction markets both tend to boost performance off that baseline. Then we invented some training modules that were designed to alert people to common cognitive biases and propose some correctives, and also give them some very simple rules of thumb for how to go about making initial estimates, especially the use of comparison classes.
You get better forecasters; you have better teams; you have better training; then you have these algorithms that take the better forecasters who have increasingly good track records, give more weight to the recent forecasts of the best forecasters, then you do some extremizing nudges that are statistically estimated from previous datasets. You just gradually get better and better at it as things unfold.
What does it mean, getting the right people on the bus? It meant several things: It meant fluid intelligence, which is that funny little test I have on the next page; active open-mindedness, which is close to this notion of being more foxlike; granularity in using probability scales. In other words, trying to make many distinctions along the 0 to 100 scale, not that you could make 100 distinctions along that scale, but trying, and seeing forecasting as a skill that can be cultivated and is worth cultivating. That’s another one of the key ingredients. You need to believe that this is possible. If you don’t believe it’s possible, you’re not going to try it, and if you’re a decision-maker and you don’t think it’s possible, you’re not going to buy it. There is some element of self-fulfillment here.
The next is the Raven’s progressive matrices. This is an interesting test that was developed a long time ago. It’s one of the oldest psychological tests. It was used in World War II by the British, U.S., and Soviet armies for identifying talent among raw recruits—kids who were coming from the countryside who didn’t have a lot of education but they thought had potential to do more sophisticated things in the military. This was a test that didn’t require words at all, it just required seeing patterns.
Then there’s the notion of granularity, this idea that it’s useful to try to distinguish more degrees of uncertainty. Think of Hillary’s electoral prospects—from 60 to 58 to 57 to 63—as events unfold, you update, and you update in fairly small increments because most of the news is fairly small and incremental. Of course, when big things happen, forecasters move fast. Usually it’s an incremental process. It’s interesting what the U.S. intelligence community believes about how granular it’s possible to be.
The slide that is numbered thirty-three has the official scales the U.S. intelligence community uses. They have recently decided—I guess it’s IC directive 203—to start attaching numbers to the verbal labels. Previously, what you had were these shaded scales moving from very unlikely to very likely; this was the five-point scale. Then they moved to a seven-point scale. Now they’re working with a seven-point scale that has numerical anchors.
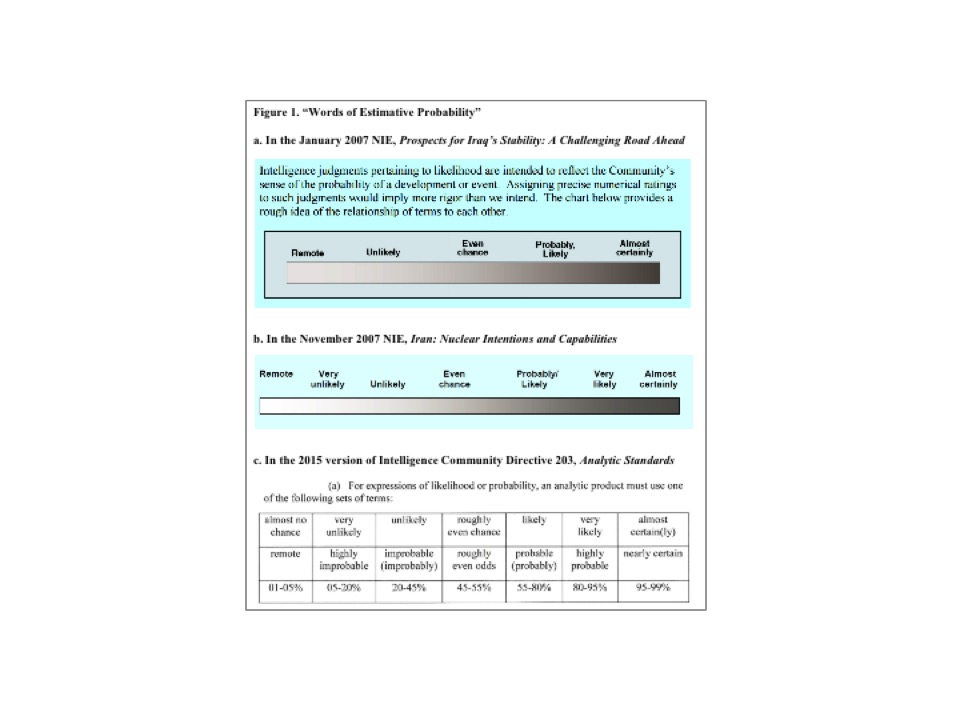
It is interesting that the IC is becoming increasingly granular; they find the idea of granularity quite interesting, at least some of them do. The next slide relates to people stimulating each other to be smarter, either through cooperation or competition.
W. Daniel Hillis: Do the customers of the IC like the idea of granularity?
Margaret Levi: Customers? You mean President Obama?
Hillis: The people who read the results.
Tetlock: It hinges enormously on who the customer is. If your customer was a Secretary of Treasury like Robert Rubin or Larry Summers, the answer would be of course, but not all policymakers are that way. My understanding informally is that President Obama is somewhat open to that. He’s not extremely quant, but he’s not averse to it. Bill Clinton was somewhat open to it. It depends on who the policymaker is. It depends on the topic and whether the policymaker is optimistic that the topic falls in the domain of probability, or whether it should be treated in some other fashion.
Rodney Brooks: I don’t know if people here are familiar with the TRLs— technology readiness levels—that NASA originally developed. Previously, there had been very fuzzy terms about how good technology was, and NASA came up with a series of technology readiness levels that are roughly ten or twelve scales, from “had been demonstrated in the laboratory,” “had been demonstrated in the field,” “was ready to be started to be integrated into a mission,” “had been on a mission.” This has been adopted in lots of places, just over the last five years, as a scale to be able to look at technology, look at that label and know whether you should use it in your project or not. I see Peter nodding.
Peter Lee: We used this at DARPA religiously, and it was also the way to guide the distribution of the dollars.
Brooks: Before that, it was very fuzzy. With those defined categories, roughly ten or twelve of them, I can’t remember. It’s been very influential in Europe. Based on that experience, by having a few explicit labels, that could change people’s ways of thinking. It did in the technology arena.
Tetlock: That is very interesting. I’ll have to think about that. By way of rapid overview of the components of the winning strategy: The right people on the bus, the teaming and the prediction markets, the training modules. We could have a full session on what probabilistic reasoning training entails. The interesting thing is the exercises themselves only require about an hour and they do produce an improvement in probability judgment over the year of about 10 percent, which, for those of you who have been in the training business know is remarkable—that the effects should dissipate far faster than that.
Hillis: Do they ever produce a decrease? I remember when people used to worry about “groupthink.”
Tetlock: They still do. You mean as a function of teaming or training?
Hillis: Teaming.
Tetlock: The teaming? Groupthink is not much of a threat in this type of forecasting tournament environment because people aren’t face-to-face. These are virtual teams. They don’t have a leader. If anything, the problem is getting enough coordination, not excessive coordination and conformity pressure. It is true that some teams do have taboos and they sometimes hurt their performance on certain questions, but the superforecaster teams are particularly good at doing this constructive confrontation process.
Rory Sutherland: Are there particular areas where the improvement is most dramatic? In other words, where the collective view, or the hedgehog view, is most wrong.
Tetlock: Are there questions where particularly opinionated people are likely to be blindsided?
Sutherland: Yes.
Tetlock: Yes, there are. Here is one quick example: It would be an odd question but, would the French or Swiss medical teams investigating the causes of the death of Yasser Arafat find evidence of polonium in the postmortem? This is many years after his death. This was a question that some people who had very strong views on the subject felt was an attack on Israel. They read the question as, did Israel kill Arafat? They did attribute substitution, once again attribution substitution strikes. The answer for them was no, it didn’t. People who think it did are nasty, anti-Semitic people. That shuts down conversation in a group pretty fast. It turned out that they did find evidence of polonium.
That doesn’t mean Israel killed Arafat; there are many ways in which polonium could have found its way into the body of Yasser Arafat. The best superforecasters unpacked those ways. They were well aware that Israeli targeted assassination of Arafat was only one of a number of possible ways polonium could have gotten into Arafat, and that put them on the higher side of “maybe.” It was a very hard question, but having a strong emotional ideological reaction to the question hurt. Slide thirty-seven, thirty-eight shows the workings of the log-odds extremizing algorithm. The basic idea here is that the more diverse the inputs into the forecast, the more justified you are in extremizing it. The more sophisticated the forecasters, that is, the more likely they are to know each other and know each other’s arguments, the less justified you are. Extremizing is typically not done on superforecaster forecasts; it is done on mass forecasts. Extremizing brings mass forecasts almost up to parity in many cases with superforecaster forecasts. You can make the masses almost as good as the superforecasters with a version of this algorithm, so it’s pretty powerful.


Daniel Kahneman: It had no advantage for superforecasters?
Barbara Mellers: It really doesn’t help them that much.
Kahneman: Isn’t it a very strong argument to keep them separate? The superforecasters interact, but if you had superforecasters working in isolation... it’s the teaming that hurt. Wouldn’t they do better if they worked in isolation and you extremize them?
Tetlock: We have multiple superforecaster teams though. Even when you’re aggregating across multiple teams, which aren’t communicating very much, you don’t get much benefit.
Mellers: The other thing about the superforecasters is that their total knowledge is much greater than those of the mass. They’re sharing that and they’re making the pie huge relative to the other pies.
Kahneman: That’s odd.
Brooks: What is the myth and reality of Zero Dark Thirty?
Tetlock: There are multiple myths and there is ultimately one reality. The myth was that there was a single female CIA analyst who said “100 percent” in the meeting. I gather that she was more reasonable than that. She was quite convinced that he was there, but a number of other people were quite convinced he was there, too—in the 90, 95 percent range. There was certainly something very suspicious about that compound in Abbottabad, but there could have been a paranoid Pakistani businessman walled up in there. There could have been a lot of different things. There could have been a different terrorist walled up in there. Using 1 or 0 on the probability scale is, in general, an unreasonable thing to do.
Robert Axelrod: Except if she wants to establish a career.
Levi: Right. Other incentives.
Axelrod: Saying 95 percent and being right is fine. Saying 100 percent and being right means you’re the go-to person. Now it’s a risk.
Kahneman: It’s a very small risk. If you believe it’s 95, it may be optimal to say 1.
Tetlock: People who do these psychometrics of probability scoring have lots of debates about what the correct scoring rule is. You want a rule that incentivizes people to report their true probabilities.
Axelrod: No, not necessarily.
Tetlock: In the tournament, we did. Brier scoring is designed to do that. It is to incentivize truth-telling. You will suffer consequences in your accuracy score if you allow self-presentational motives or emotional factors to cause you to pump up or deflate probabilities. You should be reporting your true probability. There are different types of proper scoring rules, and some proper scoring rules are extraordinarily punitive toward using 1. That’s capital punishment; you never come back if you say 1 and you’re wrong, whereas you can at least come back with much effort after 95 percent.
The question is, in your organization, how do you want to align the incentives for expressing confidence? How much do you want to reward being on the right side of “maybe,” and how much do you want to punish people who overextremize? That’s a difficult judgment call, and there is probably no one answer to that question. It’s going to hinge on the particulars of the decision and what your utility calculus is.
Ludwig Siegele: You say that the tournaments beat prediction markets, so how much better than prediction markets is it and why is that?
Tetlock: David Ignatius wrote an article in the Washington Post a couple of years ago on this tournament and he claimed from classified sources—I can talk about this only because he wrote about it—that the Good Judgment Project outperformed a prediction market inside the intelligence community, which was populated with professional analysts who had classified information, by 25 or 30 percent, which was about the margin by which the superforecasters were outperforming our own prediction market in the external world.
Many economists would say that there has to be something wrong because prediction markets are the most efficient possible way of aggregating information. How could these prediction markets be falling short? All I can say is these were the facts.
Economists would say, “Well, that’s because you didn’t have a real prediction market with real money,” and that would be their argument. Let’s face it, we have not shown in this tournament that superforecasters are capable of reliably regularly beating deep-liquid markets. That was not one of the benchmarks in the competition.
Kahneman: Deep liquid markets do not beat their own average, or barely, so wouldn’t you think that the case is closed on that?
Tetlock: I’m expressing the skepticism that economists who want …
Kahneman: Hedgehogs. You’re talking about hedgehogs.
Tetlock: People who wonder how prediction markets could have been beaten draw the conclusion that we must operationalize prediction markets poorly. In particular, they haven’t put a lot of constraints on how much we could pay people. For example, one of the most remarkable things is we couldn’t pay people for accuracy. We paid everybody the same thing whether they’re superforecasters or they’re just bumps on a log.
Axelrod: So it’s reputation.
Tetlock: They’re competing for reputation and for status, yes. An illustration here of how good they got is on slide forty.
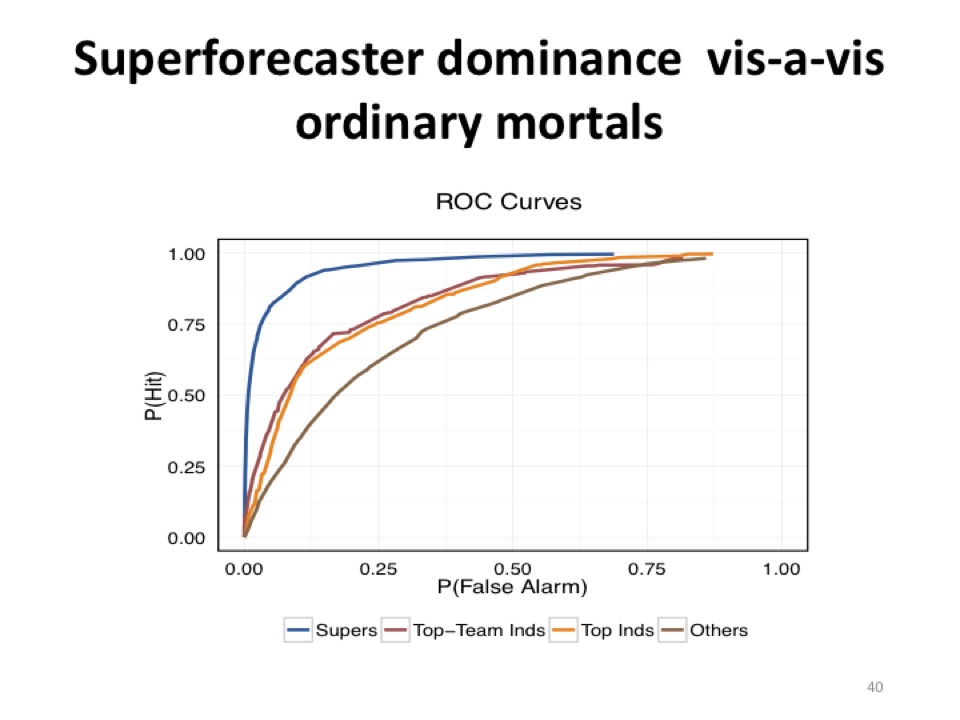
This is a receiver operating characteristic curve. The blue function rising up here shows how much better superforecasters were at achieving hits at an acceptable cost in false alarms. If you had an equal base rate of events occurring and not occurring, a chance performance would be a straight diagonal across here. The faster you rise, the better. In some other ROC curves—receiver operator characteristic curves, from signal detection theory—that Mark Steyvers at UCSD constructed—superforecasters could assign probabilities 400 days out about as well as regular people could about eighty days out.
Levi: Are we going to get back to some of the organizational design questions?
Tetlock: Yes, which is why we use this eye chart analogy. It’s analogous to seeing better.
Lee: I wanted to get back to the complaints by the economists because I suppose the simplest question that an economist might ask is, why not try to beat the market?
Tetlock: That’s an excellent idea. It’s something we should do. It was not something that was the central target of the IARPA project. IARPA had some economic questions about Spanish bond yield spreads and Euro value. There were some questions that had some market equivalence, but that was not the primary focus. It would be a reasonable thing to do.
Siegele: I wonder whether those tournaments are markets too, but differently organized.
Sutherland: Reputational currency as well as a financial.
Tetlock: There certainly is a very competitive dynamic to it, yes.
Stewart Brand: The gift economy is different than the money economy. Wikipedia, for example. Wikipedia makes no economic sense.
Siegele: It depends. If it’s a reputation thing, you get paid in reputation dollars. I don’t see why that is that different.
Brand: Reputation is patchily fungible compared to cash. I’m guessing in the direction of what’s going on here.
Tetlock: It is interesting how many of the superforecasters were quite public-spirited software engineers. Software engineers are quite overrepresented among superforecasters.
Sutherland: Not insurance company employers?
Tetlock: Not political scientists, interestingly. There are a few, but there is somewhat of an allergy to it.
Lee: That touches on something that occurred to me a little bit earlier as I was reading the framework here and you were talking about it. It looked to me like you were trying to find a way to turn hedgehogs into superforecasters and harness them to create a much stronger forecasting capability. The framework and the training that you put people through is pretty remarkable. It looked like an impressive way to create forecasting hedgehogs, so to speak. Is there something wrong with that view?
Tetlock: We were trying to encourage everyone to go in that direction. In particular, we’re encouraging people not to have tunnel vision, that solving these forecasting problems typically requires inputs from multiple perspectives. You have to look at it from the perspective of multiple actors, multiple frameworks, and if you don’t do that fairly regularly you will suffer in your reputational accuracy.
I was going to position the philosophy of the Good Judgment Project vis-à-vis four pretty famous people, and that’s on slide forty-nine.

There’s a picture of Danny, there’s a picture of Anders Ericsson, there’s a picture of Nassim Taleb, a picture of Bruce Bueno de Mesquita. In each case, we’re saying there are some basic points in which we agree, and then there are some differences in emphasis. We certainly have been heavily influenced by Danny’s work on biases, but we’re somewhat more upbeat on de-biasing. We’re influenced by Anders Ericsson’s work on deep practice. The superforecasters do engage in what Anders Ericsson calls “deep gritty practice” but were less allergic to the concept of IQ. Anders Ericsson sometimes leaves the impression that anybody can do it if you can do your 10,000 hours of practice, and we’re not saying that. It certainly helps to be at least above average intelligence if you want to become a superforecaster. Nassim Taleb, we certainly agree on black swans, extreme outlier events, and tail risk, but where we would disagree is that anti-fragilizing is expensive. You can’t anti-fragilize everything. You can’t have a contingency plan for everything. You have to prioritize and prioritize means probabilities.
Sutherland: I suppose he is now writing about this saying that, for example, there are certain things which are systemically risky like GMOs, which is worth being precautionary about. Nuclear power, not, because it isn’t the same kind of risk. If you look at nature, we do have two kidneys, two eyes, there is some degree of built-in redundancy.
Tetlock: The point you’re raising, Rory, about yes, you can anti-fragilize based on the magnitude of the consequences, I don’t think you can magnetize purely on that; you also have to implicitly or explicitly factoring in probabilities, but Nassim is skeptical of this enterprise. We did write a joint paper together in which we tried to reconcile our positions, but I don’t think we were successful. Bruce Bueno de Mesquita, a famous game theorist in political science—some of our best superforecasters use game theory in their analyses—we don’t buy into the strong assumptions about rationality as he does, and we don’t use the particular aggregation methods he uses. Although, the aggregation techniques he uses do have some family resemblance to the ones that we use.
The Good Judgment Project is pretty unapologetically eclectic. We are picking out ideas from lots of different places, and that’s what tournaments require you to do. You don’t have the luxury of saying à la Paul Krugman, “Well, I overestimated the IQ of the Greek government.” These things matter. It matters that you get your economic analysis right, but it also matters that your political analysis be right if you’re making recommendations in the real world.
In forecasting tournaments, you don’t have the option of retreating into your disciplinary castle. We, as researchers, don’t have the luxury of retreating into our favorite psychological or statistical approaches. We have to be continually innovating.
Levi: Could we go back to the participants in the tournament because that was an interesting throwaway line you gave about the software engineers. I am also wondering in the tournaments that Bob reports on in the Evolution of Cooperation, were there similar over- or underrepresentations? Both of you, I want to hear about the position of the participants.
Axelrod: My tournament is recruited from mostly the second round, from magazine ads in computer hobbyist magazines. Maybe a third of the people were professionals. In the first round they were all professionals, but there wasn’t a correlation. What they were doing was a little different than prediction tournaments. One way to think about it is that they were predicting each other, and in particular, how responsive the other players would be.
Tetlock: This is going to be a little bit of an aside, but it’s relevant. Your work on tit-for-tat—nice, clear, forgiving retaliatory—and what a remarkably adaptive strategy it can be, various people have come out over the last twenty to thirty years and offered qualifications to that thesis, either less forgiving, more forgiving, in different types of environments with different functional properties. Have you changed your mind very much? Or were those qualifications you were aware of beforehand?
Axelrod: Just barely. The major one is that if there is some misunderstanding or misimplementation. Sometimes you meant to cooperate with the other person who thought that you were defecting, then it definitely pays to be generous because, let’s say, 10 percent of the time you don’t respond and that ends the unending possibility of echoing a mistake, so that you should be more forgiving than tit-for-tat. You don’t have to be much more forgiving to do a lot better. If you know that you made a mistake, like the organization defected while you intended to choose cooperation and the other guy defects back, it pays to be contrite, which is not to echo back right away; that could be more efficient. That’s the main modification, which I was vaguely aware of when I wrote the book. It’s become much clearer about how to deal with that problem. There is a straightforward way to deal it.
Tetlock: The composition of our forecasting population, Barb, you’re probably more familiar with this than I am. A surprisingly large percentage of our top performers do not come from social science backgrounds. They come from physical science, biological science, software. Software is quite overrepresented among our top performers, isn’t it?
Levi: Are they overrepresented in your sample all together or just in the top performers?
Mellers: Overrepresented, probably. I’m not sure relative to what, but we have not for a lot of them. We have pharmacists, doctors, lawyers, sociologists.
Tetlock: We have some social scientists, but not as many as you might think.
Jennifer Jacquet: But is that just an opt-in bias? They’re on their computer all day and then they’re willing to click a bunch of questions.
Tetlock: Yes, I think that’s right. They also find it very interesting, this question here about the limits of probability. What are the limits of quantification? They find that an engaging question. They like to compete. They’re competitive. They’re curious about what the limits of quantification are, and it becomes a kind of existential mission for some of them. They really get into it.
Kahneman: Do they like puzzles?
Tetlock: They do, yes, they certainly do.
Mellers: They love puzzles.
Tetlock: If you looked at the personality profile of superforecasters and super-crossword puzzle players and various other gaming people, you would find some similarities.
Levi: That’s the question that I’m driving towards. You’re figuring out things about them from within the population of the forecasters, but what about the larger population? Are there better or worse types out there and is there a way to get at who is more likely to become a find?
Tetlock: The individual difference variables are continuous and they apply throughout the forecasting population. The higher you score on that Raven’s matrix problem—there’s a whole series of Raven’s matrix problems—the higher you score on active open-mindedness, the more interested you are in becoming granular, and the more you view forecasting as a skill that can be cultivated and is worth cultivating and devoting time to. Those things drive performance across the spectrum, and whether you make the superforecaster cut, which is rather arbitrary or not. There is a spirit of playfulness that is at work here. You don’t get that kind of effort from serious professionals for a $250 Amazon gift card. You get that kind of engagement because they’re intrinsically motivated; they’re curious about how far they can push this.
Hillis: Did you in any way measure the amount of effort they put into it?
Mellers: Yes, we did a lot of different ways, one of which is self-report. It’s hard to see how long they’re on the computer because they may have gone off and gone on a vacation or something. There is a story about one superforecaster that I liked. He’s a guy from Santa Barbara, Doug L., and he decided that he was going to only work for two hours a day on this, so what should he do for those two hours? He’s a retired programmer, so he sat down …
Tetlock: IBM.
Mellers: … and wrote a lovely program that takes into account who on his team has not updated for a long period of time, and a lot of different factors. Again, he’s a public-spirited guy. He then gives his tool to everybody on his team. That year, Doug L. came in first out of all the superforecasters and his team members came in second, third, and fourth. They’re not subjects, they’re collaborators. They’re building tools for us.
Tetlock: They are creating software tools that assist them with the work. In some sense, some of the superforecasters have already become human machine hybrids to a certain crude degree. Was it Doug L. or was it Tim who developed that program for ensuring that he got a balanced ideological diet of use?
Mellers: That’s Tim.
John Brockman: This is a program written that goes into the computer like an app? Whereas Google does this automatically.
Tetlock: It’s a way of reminding him of the sources he’s looked at on his question and whether he should be balancing his informational diet.
Salar Kamangar: Was there a correlation between time spent and forecasting ability when you looked at that self-reported information?
Mellers: Yes, in the sense of how often you update your forecast, that’s huge.
Kamangar: How about aggregate time?
Tetlock: We don’t have a good measure of that.
Mellers: That’s hard to say.
Tetlock: It’s fair to say that some people work smarter than others do in this domain as in other domains, but on average there’s got to be some correlation.
Brockman: Phil, could you do this with a cookie? Like a software ISP. Insert a cookie into an ad that goes on your machine with that program, so people that are authorized will know the information.
Kamangar: You’ll know the aggregated computer time, but they might be using it for different purposes, so you’d have to go back and look at the search history. Yes, it would be pretty interesting to be able to try track more carefully how much time was actually spent. Do you ask them beforehand to predict how well they’re going to do relative to their peers? Are superforecasters better at predicting how well they’re going to do?
Mellers: No, they are terrible. That’s amazing. But if you asked them about their expertise, there’s nothing in terms of correlations with accuracy.
D.A. Wallach: Presumably, some of the things they’re being asked to predict are more or less predictable than other things.
Tetlock: For sure.
Wallach: Do you ask them anything about their self-confidence, meaning their own ability to predict? Is there any relationship between how confident someone is about their predictions and how accurate those predictions are?
Tetlock: Barb was doing a number of variations of that from one year to the next, looking for a self-report indicator that would predict a performance on a question-by-question basis—your self-rated expertise, your self-rated confidence—and the results are fairly anemic.
Jacquet: Doesn’t that make sense? You highlight overconfidence as a blind spot and the best superforecasters aren’t overconfident.
Tetlock: The forecaster who just mindlessly internalized admonitions against overconfidence is not going to do very well in this tournament because they’re going to stick too close to “maybe.” They have to be aggressive when appropriate.
Wallach: In the real world, shouldn’t the goal be partly to encourage people to be much more pessimistic about their own predictive abilities in areas that are difficult to predict?
Tetlock: Yes. It proves to be very difficult to predict the predictability of questions. Ex ante is very difficult, but it’s not totally impossible; experts do it. You can get correlations maybe up to about .25 or so, which is something. But there are questions after the fact that you know they resolved in a remarkably fluky way, and it could easily have gone one way or the other. It was a matter of minutes, or it was just inches, or very small amounts of money or interest rates, a very small percentage of differences. We call these “close calls,” and close calls are certainly a source of serious noise in the data, but they’re not so serious that they prevent us from finding a lot of patterns.
Kahneman: There are those two dimensions, which maybe you want to explain, on accuracy and calibration which are mentioned in one of your slides. I was going to ask about the difference between superforecasters and others, how much of that is in calibration and how much of that is in accuracy?
Tetlock: Calibration is when I say there’s a 70 percent likelihood of something happening, things happen 70 percent of time. When I say there’s an 80 percent likelihood of things happening, those things happen about 80 percent of the time. Ninety, I say 90 percent, those things happen about 90 percent. My subjective probabilities correspond to the objective likelihood of events that have been assigned that probability category. Resolution, or discrimination as it’s known in the literature, is another statistical component of the Brier score, and that refers to my skill at assigning much higher probabilities to things that happen than to things that don’t happen. Superforecasters are better on both.
Mellers: They are much higher on the most important one, which is discrimination or resolution.
Kahneman: Yes, because if you give all events that happen a probability of .6 and all the events that don’t happen a probability of .4, your calibration is perfect but your discrimination is miserable.
Tetlock: If I only use .6 and .4 as my probabilities—I’m not saying anything beyond minor shades of “maybe”—I’m not very interesting already. When the things I say are .6 likely, they happen 60 percent of the time, .4 likely, they happen 40 percent of the time. Danny is saying I’m perfectly calibrated but I’m not very interesting, and I don’t have good discrimination. I’m not assigning very different probabilities to things that happen and don’t. All you can tell from Tetlock is just minor shades of “maybe,” and we typically want more from people than that.
Hillis: I notice on the black curve they seem particularly good at not having false positives, but that could also be your question. Are the things you’re asking to predict unlikely things?
Tetlock: It’s very hard for us to judge the objective truth of that. Most of the time, things don’t change. It varies from year to year how much more common the status quo is than change. Generally, change is the lower base rate event. The last year, it was about 70-30.
Jacquet: 70-30 in favor of things not happening? Is that what you’re saying?
Tetlock: Yes, in favor of the status quo. Tournaments have a scientific value. They help us test a lot of psychological hypotheses about the drivers of accuracy, they help us test statistical ideas; there are a lot of ideas we can test in tournaments. Tournaments have a value inside organizations and businesses. A more accurate probability helps to price options better on Wall Street, so they have value there.
I wanted to focus more on what I see as the wider societal value of tournaments and the potential value of tournaments in depolarizing unnecessarily polarizing policy debates. In short, making us more civilized. How might tournaments do that? The first generation tournaments we have been running are not quite up to that task because they have focused so heavily on accuracy. The quality of the questions being input into the tournaments, I wouldn’t say we have low quality questions, but we haven’t explicitly incentivized the generation of high quality questions.
Some critics would say it’s a bit like the drunkard search—the guy who looks for his keys under the lamplight because that’s not where he dropped the keys but that’s where it’s brightest. There is well-developed research literature on how to measure accuracy. There is not such well-developed research literature on how to measure the quality of questions. The quality of questions is going to be absolutely crucial if we want tournaments to be able to play a role in tipping the scales of plausibility in important debates, and if you want tournaments to play a role in incentivizing people to behave more reasonably in debates.
Here is what we know: The first thing we know is that there is a tradeoff. There is a tradeoff between rigor and relevance. Rigorous questions are questions that you can resolve in a certain time frame with absolute clarity. We know that you are on the right side of “maybe,” and someone else is on the wrong side of “maybe.” We know that there is no room for much debate about it, that’s what it means to pass the clairvoyance test. The relevant questions are questions that tap into big debates. What do policymakers really care about? What they care about is the stability of the Eurozone, and what they care about is geopolitical intentions of Putin, or what they care about is the robustness of the Chinese economy and political system. These are big questions they care about. Those are not questions you can enter into forecasting tournaments.
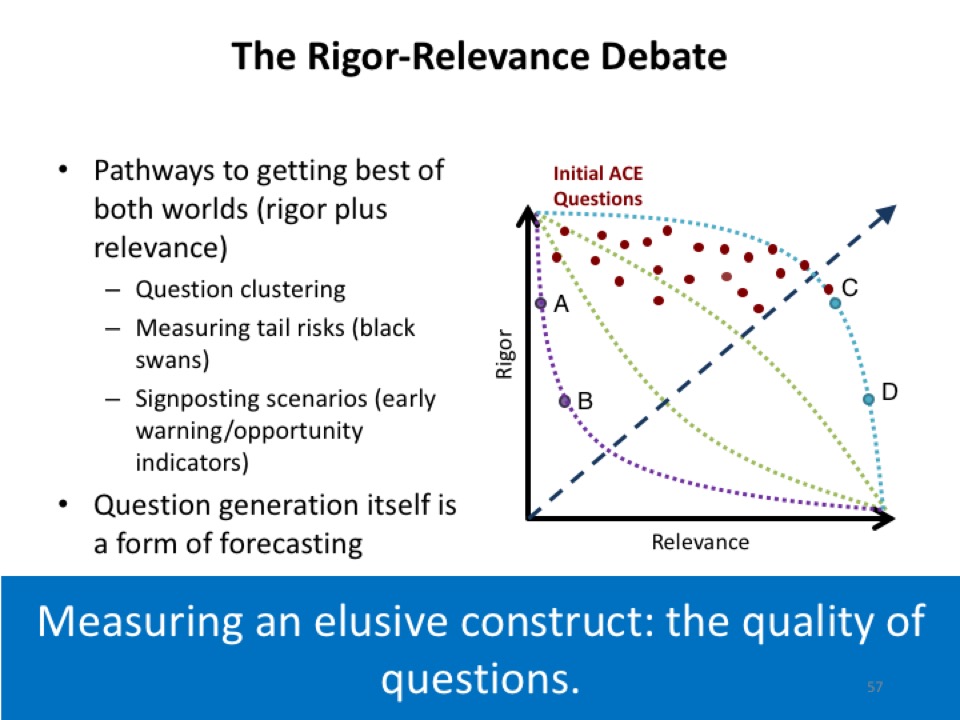
The goal here is to generate questions that are simultaneously more rigorous and relevant. You want to push out the rigor-relevance frontier, and what might that look like? The rigorous questions tend to be about small things, each of which has a small degree of relevance to a big question. It’s easy for any given forecasting question for you to shrug and say, “What do Spanish bond yields tell me about the viability of the Eurozone?” Well, not very much. “What does a clash in the South China Sea between the Philippines and the Chinese Navy tell us about Chinese geopolitical intent?” Well, perhaps not that much. What you’re looking for is creating clusters of resolvable indicators, each of which makes a significant incremental contribution to the resolution of a bigger question.
This question clustering idea: Will China become more aggressive? You want to look at whether they’re going to attempt to interdict U.S. Naval forces in a certain region of the Western Pacific, you want to look at whether or not there is a Sino-Japanese clash around contested islands in the East China Sea, you’re going to want to look at fishing rights in the South China Sea, you’re going to want to look at going after the Philippines on the Second Thomas Shoal, you’re going to want to look at selling UAVs, and you’re going to want to look at Chinese defense spending. There is a whole host of things you might want to look at.
You need to mobilize expert opinion in a systematic way to generate these question clusters, then you need to populate the tournaments with these question clusters, and then you need the tournaments to generate probabilistic answers to the question clusters that then we can look at and say, “This should tip the scales of plausibility toward a more pessimistic or optimistic view of Chinese geopolitical intent in the next twelve months, or the next twenty-four months, or the next forty-eight months.” That’s something that’s very hard to do, and it hasn’t been done on a large and systematic scale yet. We have some other examples among the slides. We have one for Russia, we have one fill-in-the-blank: How would you measure global economic volatility? What would many useful mini indicators of global economic volatility be? When I was talking at the IMF, it was very easy for people to generate lots of those.
PART 2
Brian Christian: If you ask these experts, in light of these new naval exercises, what do you think about the aggressiveness of China in general? Would it be possible to make inferences about what kind of causal network links these things, whether it’s how these different factors get weighted or whether they’re just being summed or averaged or maxed? Is there an ability to tweak these sub-questions and gain insights?
Tetlock: Yes, there is. For example, assuming that Bret Stephens’s—a conservative Wall Street Journal columnist—negative view of the Iranian agreement is correct, how likely are you to observe X, Y, or Z, versus assuming an alternative view is correct, how likely are you to observe X, Y, and Z? You’d create likelihood ratios that, once resolved, should tip the scales of plausibility a little bit toward one side or the other. Ideally, you would have the Tom Friedmans and Bret Stephens of the world nominating the questions themselves and saying, “If these questions resolved in the other direction, I would be willing to change my mind by delta.
The most ambitious of all the scenarios is one in which you would have two elite camps: you’d have a Krugman-Keynesian camp and a Niall Ferguson-Austerity camp, whatever you want to call it. You’d have two different camps on the wisdom of quantitative easing—although that’s not so much of an issue in the U.S. anymore—you would have two different camps on fiscal monetary policy, and each camp would have the challenge of generating ten or twenty questions that it thinks it has a comparative advantage in answering.
Here, victory has a clear-cut meaning. Victory means you not only answer your questions better, you answer my questions better. Then, if you come back and say, “I’m not willing to change my mind at all,” well that’s my prerogative not to change my mind, but I’m going to look somewhat foolish.
Brand: Phil, how are questions generated for the IARPA tournament?
Tetlock: Different ways at different times. Originally, they were generated by the intelligence community, and then they shifted that task to us in year three. We had a team of political scientists who worked on that.
Brand: Question generation clearly is part of the emerging discipline here.
Tetlock: It is a very important part, a crucial part. For tournaments to have a positive effect on society, we need to make a very concerted effort to improve the quality of the question generation process and to engage people in public debates to participate in that. The problem here is, and this is where I tend to come a little closer to Danny’s pessimism on this, it’s hard to convince someone who’s a high status incumbent to play in a game in which the best plausible outcome is you’re going to break even. Your fans already expect you to win, so if you win you’re basically breaking even. The more likely outcome is you’re not going to do all that well because there is a somewhat loose coupling and many pundits’ forecasting expertise probably is overrated.
Brand: You’re partway there. Question clustering is already an effort to keep rigor and move into relevance, but also you’ve got it moving toward better questions. You want to get them from the public?
Tetlock: There are other ways of doing it. There are interesting silver standard sorts of measures that Drazen Prelec, a guy from MIT who worked with us in years three and four, proposed. One of them is, in addition to asking you to predict those mini indicators about Russia, we would also ask you to predict whether an expert panel on Russia believes that at the end of 2016 Russia has become even more aggressive than it was in 2015. We don’t have a clear operational definition of what “more aggressive” means other than the expert panel consensus. It’s like a beauty contest prediction. You’re predicting other people’s views in the future where those views are determinate. In many cases, it would be quite obvious, right?
Brand: Elections are polls also, but public polling goes on all the time. Were you doing any stuff that relates to predicting polling?
Tetlock: Occasionally our forecasters were pitted against elections. The question was whether they could do better than election polls. In general, it’s very hard to do any better than what Nate Silver and other meta poll analysts do, which is essentially aggregating lots of poll results and rating the polls by quality. It’s hard to beat that as a benchmark.
There was one interesting case where the superforecasters did do that fairly decisively, and it was on the Scottish secessionist referendum. The polls were fairly close. Although if you had done a straight Nate Silver aggregation on the polls, you still would have said it would fail, but there was a lot of hype around secession and there was a lot of uncertainty. The London bookies were fairly close. It wasn’t even odds but it was getting close to that, and the superforecasters were fairly consistently saying it was about a 15 percent likelihood event. They only spiked up once when there was one poll that showed a majority for secessionists spiked up to about 30, but then they quickly reverted back in response to the other polls. What gave them an advantage there? I don’t think it’s that mysterious. There is some historical record of voters becoming more conservative prior to major votes like that, one of the most famous cases being the non-secession of Quebec from Canada.
Levi: On more than one occasion. I have a question about the cluster questions leading to an outcome that we feel comfortable with. Maybe I just didn’t understand the process, but it seems to me that each of those separate events—asking a question about China doing this or Russia doing that—may not all add up to China or Russia being more aggressive. It may be that that particular decision was just a brief decision in response to a particular thing but doesn’t add up despite there being any number of ...
Tetlock: But the clusters are tapping multiple, somewhat distinct things.
Levi: But it doesn’t mean that the end result is that the country would make a more aggressive decision on something big.
Tetlock: It doesn’t necessarily mean anything of the sort.
Levi: I’m just trying to figure out what it tells us.
Tetlock: It’s tipping a probabilistic calculus one way. It’s tipping a debate one way or the other. To make a debate more civilized, you want to encourage people to be more granular, and this is a way of doing that. Even the most opinionated hedgehogs, when they’re in forecasting tournaments, do become a little more circumspect. Barb’s evidence on open-mindedness has some bearing on that.
Hillis: This is another area where the storytelling becomes important. In some sense, the link between the questions you’re asking and the decision that you’re making depends on the model of world and the story of how things operate and so on. It may be that what people would like to have as a product is a story to believe in. These questions are ways of them reinforcing a story or not, but it might be more useful if the superforecasters, instead of just giving you a probability, gave you the alternate stories of what might happen. That might be a product that’s more consumable.
Tetlock: You’re asking the superforecasters for what?
Hillis: I would be asking them to paint me a picture of what you think is going to happen, the big story of what you think is going to happen. Don’t just answer my questions of will this event happen, will that event happen? Give me a scenario.
Tetlock: We want to move from a pointillist painting—dot, dot, dot—to something …
Hillis: In asking you to show me what colors here, what colors here, what colors here, I may be answering your question because I've got a very different picture in mind than you do in asking me those questions. It’s much easier to be a consumer of an alternative story than it is to be a consumer of a bunch of facts that don’t necessarily fit your story.
Tetlock: We certainly could ask superforecasters to do that, and some of them would be game and some of them would be good at it. There are other people who are also good at it; they might not be good at forecasting but they might be very good at broad-brush stuff. Stewart and I were talking about scenario people. Scenario people specialize in doing that.
Brand: That’s the theory of scenario planning.
Hillis: Is there a way of combining them? The forecasters are good at painting these points because they have a picture in their head. You might measure their quality by measuring how well they do at these points, but then their output might not be the points. Their output might be the story.
Tetlock: Congress has asked the intelligence community to project out twenty years—scenario exercises. From a forecasting point of view, this is an extremely tenuous exercise. The National Intelligence Council is responsible for creating something called Global Trends. The most recent Global Trends document was Global Trends 2030. I guess that’s fifteen years out. I don’t know exactly when it was written; it took a long time in preparation. There are scenarios in the National Intelligence Council’s Global Trends 2030 that you could take from that document where you could say, “Here is a ‘Doomster China Implosion Scenario’ by 2025.” That would be a big cluster of questions, the China scenario. What things would we be more likely to observe in 2016 if that scenario were true? And what would we be likely to observe if that were false? You would push your subject matter and think of early warning indicators of which historical scenario trajectory you’re on.
Hillis: That’s pretty much how the intelligence community operates, but I’m suggesting a different way of operating.
Tetlock: It’s actually not, but it’s how they should. It would be a step forward if they did operate that way.
Brand: It’s too limited, Danny. I’m more and more going in the direction that narratives always mislead. I saw it with scenario planning. Part of what we’re seeing here is a cure; Danny’s perspective on things is a cure, and this here is a cure, you’re taking stories seriously. We are cognitively so wired to love stories that it gets in our way.
Tetlock: What if it were the case that we lived in a world in which the superforecasters have virtually no ability to explain and the people who are good at generating explanations are not very good at forecasting? What if the skills were radically dissociated? How would we want to organize the intelligence community or any organization for that matter that has to engage in foresight?
Hillis: Do you think that’s true?
Tetlock: That’s too strong, but it’s an interesting question to ask. There are certainly different skill sets here that are at work, and they’re not as tightly correlated as often supposed.
Kamangar: The conflict I see with this approach is, what do you mean by story? When you make a prediction, there’s a story underlying that prediction. What you really mean to say is that if I’m going to make a prediction that something is going to happen, I should accompany it with basically ten stories. If my prediction is based on ten different possibilities that I’ve calculated, I should say, “Story one, there’s a 60 percent chance that it’s going to happen. Story two is this.” We’re not necessarily saying that there should be one aggregate story. If you have one aggregate story and you try to tie all these things together, you have information loss and that makes it worse. It would be a mistake to try to have one story an established pundit would have to tell because of the information loss. It might help to accompany your prediction with the stories that you’ve based your prediction model on. You were saying you should add that storyline to it; it doesn’t have to be one aggregate story, but it could be basically a breakdown of the prediction model that you created for yourself.
Levi: A good predictor would be updating those stories with new information.
Sutherland: In your parallel world—and this is obviously someone from an advertising agency speaking—the perfect solution would be for the superforecasters to hire good storytellers to dress up their predictions in a way that was easily spread. There is a value to shamanism, correct? In order to unify human action, there’s a kind of shamanistic value to a good story, which it coordinates people magnificently.
Mellers: The problem with that is, how do we decide which one is a good story and which one isn’t?
Wallach: The question that your alternative reality is raising for me is, if people are not even blatantly narrativizing their predictions, what could possibly be going on in their heads? How do they get from point A to point B? If you were to compare investors, say, who make decisions based on gut instinct—which we generally regard as stupid—Warren Buffet, for example, would say, “Every decision I make, I can tell you exactly why I think the world’s going to play out this way, and that’s why I’m doing this.”
Tetlock: There has to be some implicit mental model behind what they’re doing. It may be though that the mental model narratives that are behind the superforecaster forecast are a tad boring. It may be that when you ask a superforecaster, how likely is a given incumbent leader in a sub-Saharan African country going to be in power one, two, three, four years ahead? The superforecaster looks at a base rate of dictator survival, and then makes some simple updates on the basis of domestic political unrest and gets a probability that way rather than telling a rich story.
Wallach: That’s a good story though. If it turns out that that’s how the world works, then that’s an exciting story for someone to have uncovered. To Danny’s point, it seems like nothing bad can come out of asking people to explain how they’re thinking.
Brockman: Isn’t calling someone a superforecaster a story?
Tetlock: Yes, actually it is.
Levi: It’s certainly a narrative.
Brockman: How do they get named? Do they join the superforecasting team? Say you’re a Kahneman. One guy, who did not show up, said, “I’ll sit there being a skeptic and who cares, right?” He didn’t want to come to this event. Danny’s hallmark is skepticism and, to some degree, you wouldn’t join a team called The Superforecasters. It sounds like a Marvel comic.
Kahneman: I mean, if invited…
Brockman: Say there is a more neutral name or a less dorky name than The Superforecasters. You’re going to get software programmers to be superforecasters because cool people wouldn’t want to be part of that.
Sutherland: The Isaiah Berlin essay, where he mentions the distinction between hedgehogs and foxes, was a piece of literary criticism, wasn’t it? It’s a long time ago, but I seem to remember the ultimate fox in Isaiah Berlin’s view was Shakespeare. It was about Tolstoy, wasn’t it?
The ultimate fox in his view was Shakespeare, who is a pretty good storyteller. There is an argument that there is foxy storytelling and there is hedgehog-y storytelling.
Levi: And there’s an argument about which is more boring.
Sutherland: The thing that you’ve got to be terrified of is the hedgehog story. We were talking about Harvard Business Review case studies of businesses that are successful, and every single piece of success is attributed to those things which the people who write such articles think to be important. There is massive selection bias in terms of to what they attribute success. No one has ever tried foxy business writing—the foxy business case study—but it would be a lot more interesting and a lot more accurate.
It’s a little like that thing, by Peter Medawar, that scientific papers are slightly dishonest because they completely misrepresent the means by which people arrived at the insight as if it was much more sequential and logical than the reality that it depicts.
Tetlock: The reason there’s not a big market for foxy case studies in business schools is because MBAs would probably recoil from them and business schools are pretty customer-friendly.
Sutherland: We just had this argument last night, which I found quite interesting. If you talk to people about Uber, the standard definition and the explanation for its success is all about disintermediation and supply chain, blah blah blah, and our argument is that it’s just a psych hack. Previously when people phoned for a taxi, there was a period of irritating uncertainty between booking the taxi and its arrival: “Is it there yet? Has he parked around the corner? What if he’s got the address wrong?” With Uber, you can look at it on a map and it removes uncertainty. People prefer that, and that’s the story. To me, because I’m interested in psychology, that’s a much more heroic explanation. No one writing a business school case is going to talk about that. That will get about one paragraph. The ease of payment, where you can just get out of the cab and say “Goodbye,” which in actual human behavior is probably quite a big factor.
Tetlock: The truth can sometimes be very prosaic.
Sutherland: In depictions of military success, no one ever says the battle of Agincourt was won because it was muddy, for instance.
Tetlock: I think we’re talking about the same thing.
Levi: Your question, Barb, about better stories and worse stories and how you tell, you mean stories that have to do with accuracy of prediction? It’s certainly not the aesthetics that’s driving it.
Mellers: There are people who don’t believe the numbers about the story. That’s what we’re talking about right now. Then there are people who don’t believe the story without a number and we need the story. What’s a good story? We know what a good number is, we sure don’t know what a good story is.
Tetlock: Rory’s suggestion is a pretty good one. It’s pretty cynical but it’s pretty good.
Kahneman: Hire storytellers.
Wael Ghonim: A good story is one that converts more people. We'd look at conversion rates and that’s what would make a good story.
Levi: But that’s not necessarily the best explanatory story, right? That’s the story that moves people.
Ghonim: It goes back to what the goal is. We were talking about the 2003 Iraq situation: If one of the questions that we were asked at the time was how influential Iran will be in the whole world right after the invasion of Iraq and removal of Saddam, and if most of the superforecasters believe it will be highly likely that Iran will be much stronger, the story could have changed public policy and could have added a lot of pressure.
Tetlock: There certainly were some very prominent political scientists, realists who were saying exactly that before 2003. They thought you were destroying the balance of power, essentially, in the Middle East.
Axelrod: Let me tell you about storytelling that I researched. This is the case of Jimmy Carter’s decision about whether or not to execute a hostage rescue for the Iranian hostages. They took several months to decide this, and there was about eight or ten people involved, so they did it with experts and with care. They knew the stakes were important.
If you look at the debate—how they went about reaching this—it was almost all storytelling. It was a form of historical analogy. For example, one of the decision makers was in Israel at the time of the Entebbe rescue when the Israelis pulled off a very long-distance, surprising and successful hostage rescue. He said, “We ought to try it,” based on that experience.
Somebody else said, “I was involved when the North Koreans took the Pueblo boat hostage and wouldn’t release the crew until we apologized, but we could try a hostage rescue. We decided not to do a hostage rescue because it was a little too risky and we thought that diplomatic means would eventually work." And they did. They released them without a military operation. He said, "Based on my experience, we should try diplomatic methods longer.” This was a military person. Altogether, there were about eight examples of hostage rescues that were mentioned, each of which was either diplomatic or military and each of which is now known to be a success or a failure. I tried the exercise like you would present it of, “How do you aggregate these eight cases into a judgment about what will work in this case?” For example, if there were a lot of hostages, it should make it harder for a military operation to work. If it was in a territory that was immediately controlled by hostile forces, that should make it harder, and so on. I tried coding all these by plausible criteria and coming up with an estimate.
That’s not at all how these people did it. They all did it by saying their single case was the most relevant and what was surprising was that the cases that people cited were almost all cases that they had a personal experience with and not whether it was more similar to the current case or not.
There was a lot of censorship on cases. For example, you may remember that Mussolini was rescued by Hitler when he was first captured by the partisans, and that worked. It was done much like Entebbe; the rescuers pretended to be the authorities, basically. Nobody mentioned that one because we don’t want to learn anything from what Hitler had done, even if he was good at hostage rescue.
Tetlock: Yes. That’s a taboo historical analogy.
Axelrod: For our purposes about prediction, the striking thing was that the number of cases that seemed to be relevant to the current policy debate, which I hope we get into—the relationship between prediction and choice—was finite and identified but not aggregated.
Kahneman: Could it have been aggregated?
Axelrod: Yes. There are several ways of doing it, one is by selection: which of these cases is most similar to the current case? Let’s go with that. A better way to do it is: which four out of these eight are most similar, and what are the odds of success if you do a military operation? There are ways of starting that process, but nobody did that.
Sutherland: There’s a big path dependency there, isn’t there? If you negotiate, it doesn’t preclude military action, but if you engage military action, it completely changes your negotiating power.
Axelrod: Everybody was game to negotiate for a few months, but when that few months was over, negotiation didn’t seem to get anywhere.
Hillis: How much of the discussion was an honest attempt to evaluate the situation and make the correct decision versus an attempt to justify the decisions? In other words, people came in with a predisposition towards diplomacy or not, and then they told the stories to justify what they had already decided.
Axelrod: There is no direct way of knowing that, but in most cases the stories that they told were the ones that convinced them.
Brand: It’s interesting, the power of experience being so overwhelming in that.
Axelrod: It is. That’s what stuck with me, which isn’t so much available in tournament format and maybe it’s good that it’s not. Maybe we need techniques to avoid overdependence on personal experience.
Let me give you another example that’s even more compelling. When Lyndon Johnson, in ’65, was considering whether to escalate American involvement in Vietnam in a big way, there was also a debate. They also took some time and also about a dozen people, and the one naysayer was George Ball who said it would be like the French experience in Indochina, that they would see Americans as foreigners and there would be a strong nationalist and broad objection, and it would basically fail. It turned out that he was in Paris during the Dien Bien Phu disaster when the French did lose, and he was working with the French government, so he had a personal experience with the French defeat that the others didn’t have who all looked at it as, "The French don’t know how to fight, the American Army knows how to fight, so don’t bother me with that experience." Johnson made a real effort to say, “Write this up. I want to hear this.” Rusk testified at Congress later that he never understood what George Ball was getting at, even though he said it over and over and explained the historical analogy. Getting from the question of how do you make point predictions to the question of how do you make decisions on a policy question is worth contemplating.
Tetlock: The ultimate goal is to bridge those. The path to that objective lies through question clusters. We have to have clusters that are simultaneously rigorous and relevant to big issues that then can funnel into the decision process.
Axelrod: That will help, but you haven’t gotten into, what might we do about this situation? You did mention as a possibility that you could say, if the United States does X or Y, what will happen, and then you could see whether people are good at understanding the consequences of choices. But then you have to consider, too, what are the options?
Tetlock: There’s a big difference between making forecasts that are not at all contingent on action and making forecasts that are contingent on action. The direction that IARPA has taken has been very much toward conditional questions on action, which suggests that they want to get to where you want them to get.
Axelrod: The intelligence community is institutionalized in the United States to separate choice from prediction, and there’re good reasons for that. Ultimately, it seems to me that as citizens we’re interested in proving the quality of the decision.
Hillis: Your story does answer Barb's question about what makes a good story, which is what makes a good story is being able to present a set of predictions in a way that people can personally relate to. If you can show us the facts or paint a picture of the world that people can see, “Oh, that connects to my own personal experience,” that’s a good story.
Axelrod: It could be a national experience, like Munich. For decades, that was a compelling story.
Kahneman: It’s not a characteristic of the story, it’s a characteristic of the people who hear the stories. What makes a good story is a story that will be convincing. That’s what your Dien Bien Phu story highlights.
Axelrod: Can I raise another question about predictability? Your emphasis has always been on, can a forecaster predict the world? Another question, in international politics especially, is can the world predict the United States, for example? Sometimes it pays to be predictable, sometimes it pays to be unpredictable.
Let me give you an interesting case in the lead up to the Korean War. The United States officially said that we have a defense perimeter—this is in February, 1950—that runs from Japan through the Philippines, and countries beyond that will have to take care of themselves. We have no commitment to them. This was based on the idea that with military, there is no point in having a defense line with some hill out there that’s unprotectable. You should draw a line that’s defensible, so we did, and we announced it. Korea was clearly beyond that line, and we had no commitments to Korea.
Mao and Stalin were both asked by North Korea whether they would support an invasion from the north to the south, and they both said yes because the United States has just announced that they will not protect South Korea. What more can you want? Perfectly predictable, right?
When Truman heard that the North Koreans invaded the South Koreans—he was at home in Missouri—he got on a plane, and by the time he got off the plane he decided that this would not be acceptable and we would do whatever was necessary to overcome this invasion. He got off the plane and he told his advisors, and they all agreed with him. Instantaneously, he made another choice, which made the United States completely unpredictable. We would have been much better off to be predictable. If we said we would defend it, they probably would not have attacked, and if we were predictable in the other direction we wouldn’t have defended it and we wouldn’t have had the war. I find it fascinating, this question of when you want to be predictable, can we make ourselves predictable?
Brand: Part of the byplay of threat and military stuff is being able to make the case that Nixon was crazy; he’d make a deal with anything. The unpredictable becomes a quasi-military advantage, and it’s been used many times often with success.
Kahneman: The very idea of announcing a perimeter which suggests that you will not defend beyond it, that is probably a mistake in many cases.
Brand: You throw away an option.
Axelrod: What we didn’t understand about ourselves was that we would react very differently when the consequences of our current announcement were made. We just didn’t think that far ahead.
Levi: We weren’t good predictors.
Axelrod: We didn’t predict ourselves.
Levi: That’s what I mean. We weren’t good predictors of ourselves.
Axelrod: You’d think it would be the easiest thing, and it was the same Administration. The characters hadn’t changed at all, and it was only a few months difference.
Tetlock: But the realities of the invasion were so sudden and brutal and reminiscent of …
Axelrod: And the story with Munich. Truman said to himself, “We appeased Hitler and he kept asking for more. If we do the same, Stalin will keep asking for more, and eventually it’s going to be World War III.” That’s what he came up with immediately. That’s what he told the American public and that’s how they conceived of it, which was extremely different framing than what is the best way to draw a defense perimeter.
Kahneman: He might have been right that it was like Munich given that they had attacked. That is, clearly the mistake was with the announcement.
Axelrod: Exactly. They should have predicted that that’s how they would react later. If they could have predicted themselves, literally themselves—Truman and Acheson—a few months later on a situation that they focused on carefully and made a public announcement, this is not just something they didn’t pay attention to, they couldn’t predict themselves, and they got into trouble.
Ghonim: I have a question about the tournament. Do you communicate to the superforecasters how they perform versus others? Does that correlate positively or negatively with their future predictions? If I am a superforecaster, is it better to communicate to me that I am a superforecaster or is it better to not give me that piece of information?
Tetlock: I see what you’re getting at. You could imagine randomly selecting a group of people and calling them superforecasters even though they’re not superforecasters. You could imagine taking people who are performing at a super level and never calling them superforecasters, and what would the impact of those manipulations be? Given the horse race dynamic of this tournament, we didn’t think we had the luxury of testing those Pygmalion type effects, but they’re very good questions.
Ghonim: If I am perceived as a superforecaster and know that, that does get into me psychologically. I’d probably be more attached to my forecastings, so it has the opposite effect.
Levi: You want to maintain your reputation.
Tetlock: That’s true, and superforecasters do not regress towards the mean nearly as much as the people who are just below the superforecasting rank. They do hold onto their position quite tenaciously.
Ghonim: But did you inform them?
Tetlock: Yes, absolutely. People each year wanted to achieve that status, and now we have 300 or 400 superforecasters. Some of them put it on their résumés.
Lee: I’m just reflecting on what Bob and Danny have been saying. There is something about storytelling that must have psychological effects, probably comforting effects in the case that your prediction turns out to be wrong. I’m just putting myself in the shoes of someone who was involved in Entebbe and now maybe that has persuaded me to make a certain prediction that if it turns out wrong, at least looking at my own psychological fragility, I might say, “Well, it worked out in Entebbe, so…”
Tetlock: “I was wrong, but at least I had a good reason for being wrong.”
Lee: Yes.
Jacquet: Isn’t this like McNamara and The Fog of War? That’s essentially what he is doing; he's telling a story about being wrong. That’s the whole film, right?
Tetlock: I would just say that this is an incremental learning process: learning how to design forecasting tournaments, learning how to assess accuracy, learning how to design better questions, learning how to create question clusters that can help tip the scales of important debates, and then finally, linking up to decision making, which has definitely not been done, partly for institutional reasons and partly also because we don’t know how to do it well yet.
There are some formal glib answers you can give to how to improve probabilities translated into different decisions. You could say, “Wall Street is often quite obvious when you’re pricing options. Those option prices have probabilities essentially woven into them.” If the probability of oil price going below $50 a barrel over the next six months is X, that has a direct impact on future contracts. You could do your expected value MBA equations and you can crank out the right answer; there is a mathematical framework for entering probabilities into the decision calculus.
In many of these other domains, it seems to be more qualitative. It’s sometimes called in psychology “reason-based choice,” and it’s a question of how much would a probability have to be nudged in order for the Director of National Intelligence to decide that the Russians are likely to go into Crimea. When Danny and I were talking to the Director of National Intelligence about the IARPA Project, one of the questions we asked was, if you had known in the summer of 2014 during the Sochi Olympics that the Russians were going to move into the Ukraine, if you had known—during the Sochi Olympics, the probability of the Russians going into the Crimea was .001, there was a sudden spike upward to .25—would the United States have done something different from what it did?
This is a question of how do changes in probability map onto propensity to act? That’s not well-defined at all. The finance realm—expected value equations—that’s well-defined, but this other realm is kind of murky and difficult, and that’s part of what’s bothering you.
Hillis: There is a completely different way of connecting predictions to positions, which is here are some decisions to make and you look for the predictions. You could also look for the actionable things that you could do if you could predict something. For instance, financial things, if I told you for sure I can predict the price of palladium, then I can buy palladium if it's going to go up and sell it if it’s going to go down. It might be that the way to, in some sense, harvest people to predict is to generate from those actions that you could take with knowledge.
Tetlock: That’s very interesting. The approach I was describing to clusters was, how likely is the question to resolve one or the other way if it were true that, say, Friedman’s diagnosis of Iran or Bret Stephens’s diagnosis of Iran is true? An alternative way of doing it would be making it contingent on action rather than on the resolution of a big issue.
Axelrod: No, but he’s also saying that a good question has to do with choices available.
Levi: Right, and what the likely consequences are.
Tetlock: I’m trying to frame exactly how you would ask the question. You’re really onto something there. You would want questions that would tip the action calculus.
Hillis: You want actionable questions. Part of that is choosing actions that follow the questions. The way we acknowledge this process works now is people ask these very big questions like, “What are Chinese leaders intents?” Again, somebody has to translate those into more specific questions and more specific questions and more specific, and by the time the answers trickle back up, they don’t have any connection to the decision people have to make. And so we’re resorting to these indirect methods like telling stories and so on to try to reconnect them.
Tetlock: Think of those things that if the probability lurched up by 10 percent, United States would be more likely to do X, Y, or Z; that’s a very hard question.
Tetlock: No? Is that not it?
Levi: Well, it’s more like what’s the mapping? Given the questions, what’s the mapping of actions that then become reasonable, possible, plausible? Once you have those, it’s the question of given whatever your incentives are or given probabilities, what do your choice structures look like? Is that closer, Danny?
Tetlock: There’s something appealingly decisive about what you’re saying, yet, k it’s very risky to bypass all the discourse that surrounds these things. There is this massive talk about Iran or about China, and there are these schools of thought that are linked up to policymakers on one side or the other—either people who are out of power temporarily or are in power temporarily—and the forecasting tournament clusters have the valuable function of connecting up to that political reality.
Levi: This other approach doesn’t have to disconnect. I don’t see that as an either, or.
Tetlock: Maybe not
Kahneman: The question clusters clearly are appropriate when you’re trying to define intent because when the other side has a general intention to do something, there are many possible actions with that general intention. It would help you a lot if you said there were questions about the intent. Have you codified what other kinds of things lead to question clusters because intent clearly does, but I’m just struggling to find out what else does.
Tetlock: Strength questions: Propensity to collapse, propensity of the Eurozone to collapse, or propensity of China. Those sorts of things.
Kahneman: Good. Thank you. Strength and intent.
Tetlock: That’s a lot.
Kahneman: We have talked about question clusters a lot. I understand what we've been saying a lot better this morning because to say intent and now strength is very clear.
