
Philip Tetlock: Welcome. There really should be two people on stage here. Barb has been, not only my life partner, she's my research collaborator on this. Without her there wouldn't have been any IARPA forecasting tournaments with the intelligence community. It's hard to say where her work ends and my work begins in the IARPA project. My rule of thumb is that Barb does the deep scientific work and I do the public relations. That's the division of labor. I should also thank John and his crew for all their help: Katinka, Max, Nina, and Russell.
I wanted to say a few words about Danny Kahneman and his role in all this. I'm not sure he remembers all the different things he's done over the last twenty-five, thirty years, to facilitate all of this. In the beginning, I was doing very small-scale forecasting tournaments. I was at Berkeley and remember in the late 1980s—I don't know if Danny remembers—he went to Chicago to the McArthur Foundation to argue that McArthur should be supporting forecasting tournaments. They did eventually come up with something, not nearly as much as I wanted, but they came up with something. That was very helpful.
Conversations with Danny through the years have been very helpful in thinking about this. We had lunch at a Chinese restaurant—I think it was called Yen Ching—in Berkeley, in the late 1980s. He had offhandedly tossed off this remark that he thought the average political expert would be hard-pressed to beat, in a forecasting tournament, an attentive reader of the New York Times. And that's been a benchmark that some of my political science colleagues have been struggling to beat ever since.
He also has been very helpful in trying to persuade the intelligence community to take the lessons of the forecasting tournaments seriously, so he did Amtrak down to D.C with me last year to talk to the National Intelligence Council and the Director of National Intelligence about the value of explicit probability scoring, learning from feedback. These might seem like truisms to scientists, but they're still quite radical, even revolutionary, ideas in much of the intelligence community. I'm not implying that he agrees with everything I'm going to say. We certainly have some differences of opinion and I'm probably more of an optimist than he is on the degree to which people will ultimately embrace these technologies, but he has been very helpful, so thank you.
I'm going to start this conversation off with a couple of stories that provide a nice point of entry into the 130 slides that you have in front of you in this notebook, and I'll also offer the reassurance that I have no intention of frog-marching you through all 130 slides. As issues come up, we might refer to particular things in here, but we're not going to go through these slides one-by-one.
It would be useful if we went around the table because I'm having a very hard time seeing people beyond about the middle.
John Brockman: Just state your name and what you do in thirty seconds or less.
Robert Axelrod: Political scientist from Michigan. I do game theory international national security.
W. Daniel Hillis: I'm an engineer
Danny Kahneman: I'm a psychologist.
Anne Treisman: I'm a psychologist.
Salar Kamangar: On leave the last year, but my last role was leading YouTube for Google, which I did for about five years.
Wael Ghonim: I used to work for Google as well. I'm a political activist and now working for a startup called Parlio.
Ludwig Siegele: I'm a journalist. I cover technology for The Economist.
Andrian Kreye: I am a journalist and I run the Feuilleton, the arts and essay section of Süddeutsche Zeitung in Germany.
Brian Christian: I'm a writer, and I write about mostly the intersection of computer science and philosophy.
Katinka Matson: Co-Founder of Edge.
Max Brockman: I'm here with Edge.
Dean Kamen: I'm an Edge groupie. When I'm not doing that, I make stuff.
D.A. Wallach: I'm a musician and investor.
Rodney Brooks: I'm a reformed academic and I make robots.
Rory Sutherland: I work for Ogilvy & Mather in London, the advertising agency, and also write on technology for The Spectator.
Peter Lee: I work at a place called Microsoft Research.
Jennifer Jacquet: Environmental Social Sciences, NYU.
John Brockman: Editor of Edge.
Stewart Brand: The Long Now Foundation and Revive & Restore for de-extinction.
Margaret Levi: Director, Center for Advanced Study in Behavioral Sciences at Stanford—CASBS, as it's affectionately known—and a political scientist.
Barb Mellers: Psychologist at UPenn.
Tetlock: I said I would start off with a couple of stories, and that's exactly what I'll do. The first story is about President Obama and the search for Osama bin Laden. In 2010, early 2011, evidence was gradually accumulating about the location of Osama bin Laden. The intelligence community was growing more confident they knew where he was, and as the confidence grew they started reporting higher up in the hierarchy. They reported to Leon Panetta, then Director of the Central Intelligence Agency, and eventually directly to President Obama. They made presentations to both of these men, and in these presentations they made probability judgments about the likelihood that Osama was indeed residing in that mysterious walled-up compound in the Pakistani town of Abbottabad. There is a version of this in the movie, Zero Dark Thirty, which we have checked out—Dan did a great job checking out with the people who were actually there—so don't believe the movie.
The movie is not too far off in this particular sense. They went around the table asking the advisors and the intelligence officers what they thought the likelihood was of Osama being there. The probabilities ranged from about 35 percent to 95 percent with a median of about .75, so 75 percent. President Obama looked a little bit frustrated and he said, "Seems like it's a coin flip, 50-50." And that was that for the purposes of that meeting.
Did President Obama utilize the probabilities in the right way? Did he draw the right conclusion or inference from the information displayed in that meeting? Bracket that question. Now move to a thought experiment in which President Obama has the advisors around him and, instead of offering a dispersion of probability estimates, the advisors all say the same thing—they all say 75 percent. Let's also stipulate for our thought experiment that the advisors have overcome the siloization problem that the U.S. intelligence community was severely criticized for after 9/11: The notion that they weren't sharing information enough. Overcoming siloization means that each advisor knows what every other advisor knows. They all know the same thing, they've all conferred on what probability should President Obama take from that. In effect, I'm stipulating that the advisors are intellectual clones of each other, they're cognitive clones of each other. The probability is presumptively 75 percent. It's as if one person were speaking to them.
Imagine a version in which all the advisors say the same thing—75 percent—but they haven't overcome the siloization problem. One official has access to satellite reconnaissance, another has code-breaking, another has spies on the ground, another has cell phone data. They all have different information, and they're siloized, and they say 75 percent.
What's the correct probabilistic inference in this situation? The answer is mathematically indeterminate. I haven't given you enough information to answer it, but it is something that can be statistically estimated. Barb and the top statistician for our project, Lyle Ungar, and other people have developed algorithms for estimating the extent to which you should adjust your probability when you have diverse inputs into an estimate. Does everyone have an intuition about the answer here?
Axelrod: Depends on the correlation among the information.
Tetlock: It depends on the correlation among the information, but we're assuming some diversity and a moderately low correlation.
Axelrod: It's got to be higher than 75.
Tetlock: It's got to be higher than 75. But how much higher is indeterminate because we don't have enough information. If you were running a forecasting tournament over an extended period of time and you had, say, 500-plus questions and thousands of forecasters, and you have estimates of diversity and accuracy over long periods of time, you can work out algorithms that do a better job of distilling the wisdom of the crowd than, say, simple averaging. It sounds risky, but it's an algorithm known as extremizing, and it works out pretty well.
Those are all thought experiments with everybody saying the same thing—75 percent. If we go back to the real world in which President Obama got the dispersion of estimates, imagine another situation: President Obama is sitting down with friends and they're relaxing and watching a March Madness basketball game. He's a fan of March Madness. There is going to be a game between Duke University and Ohio State, and the people around him make estimates on the probability of Duke winning. The estimates are exactly like the estimates we got on Osama; they start around 35 percent, they go up to 95 percent with the center of gravity around 75 percent.
Do you think when his buddies offered these odds estimates, President Obama would have said, "Sounds like 50-50 to me"? Or would he have said something like, "Sounds like three-to-one favoring Duke"?
Three-to-one favoring Duke. It's an interesting fact that in very high stakes national security debates and in many other types of high stakes policy debates as well, people don't think it's possible to make very granular probability estimates. Sometimes they seem to act as though “things are going to happen,” and there's "maybe" and "things aren't going to happen." Sometimes they act as though there will be only three levels of uncertainly. Sometimes they might act as if there are five or seven.
One of the things we found in the IARPA forecasting tournaments is that superforecasters collectively can distinguish many more degrees of uncertainty even than seven. It's an interesting question of how useful that is.
It is possible to make more subtle and granular distinctions among degrees of uncertainty on questions that are of interest to the U.S. intelligence community. That's an empirical demonstration from the IARPA tournaments; it's pretty solid. The juxtaposition of President Obama on the Osama problem and on the March Madness problem illustrates that it's not that he can't think in a granular way about probability. He may be implicitly thinking it's impossible to think in a granular way about national security, or it's not even normatively appropriate to become all that granular in the national security domain. Different epistemic norms seem to govern what is or is not appropriate to say about uncertainty.
In the handout that accompanies the slides, I've got a page on which I pose the question, what are the limits on probabilistic reasoning? Do you know? Does anyone know?

It's fair to say that the vast majority of college-educated people believe that probability theory is useful in estimating the likelihood of a fair coin landing heads five times in a row. They think probability theory is useful if you're playing poker and you're drawing cards from a well-defined sampling universe. These are classic domains for frequent disk statistics. The question we're confronting here is, what are the limits on the usefulness of probability? To what extent is it useful to elicit probability judgment for seemingly unique historical events? On this page, I list a number of situations in which people find it vexing to make probability judgments. The first one is, is there intelligent life elsewhere in the Milky Way? I don't know. There is Drake's formula and there are various estimates, various ways of trying to guesstimate things like this.
I don't think I personally can do much better than say, "I certainly don't think it's impossible, and I don't think it's 100 percent certain, either. It's somewhere between .0001 and .9999." Can I do appreciably better than that? Is granularity possible? As Kepler keeps discovering more planets and we find more planets' inhabitable zones, and eventually we pick up atmospheric signatures of oxygen and so forth in the atmospheres, we might start changing our estimates. We're still at such an early stage. I don't think I can do much better than that.
Then there are a lot of other questions that are listed here, and we don't need to go through each of them now. The question I want you to keep in the back of your mind concerns the probabilities of these types of questions: Can the answers be meaningfully guesstimated? On which ones do you think it is possible to offer meaningful guesstimates? On which ones don't you think it's possible? Why? That's essentially a question about the limits of the usefulness of something like an IARPA forecasting tournament. IARPA is, in a sense, stretching the limits of the usefulness of probability.
That's one story I wanted to use to capture one of the big issues we'll be grappling with. The second story is the parable of Tom Friedman and Bill Flack. It's a tale of two forecasters. Everybody around this table knows who Tom Friedman is. He's this world famous New York Times columnist, award-winning columnist, and award-winning writer. Tom is a regular at Davos, on CNN, he's been in the White House many times, in the Oval Office many times. Recently, Barack Obama gave him privileged interview access on the Iranian nuclear deal. This is not an unusual event in the life of Tom Friedman. Then there's this guy, Bill Flack. Bill Flack is a retired irrigation specialist, who worked for the U.S. Department of Agriculture in Nebraska. He has no track record of writing on world politics. He's never been invited to sit on a panel with Tom Friedman or, for that matter, anybody else. The question is, who is likely to be a better forecaster? You don't have to answer it out loud. This is something where Danny Kahneman's attribution substitution heuristics start to come into play in a big way. There is obviously no doubt in our minds about who is higher in the academic or policy social pecking order. Tom Friedman is one of the most famous, well-connected journalists in the world, and Bill Flack, let's face it, is a nobody in Nebraska. There is also no doubt about who the more acclaimed and prolific writer is on topics that are relevant to the IARPA tournament, and Tom is good at turning a phrase. He's written some wonderful columns, in my opinion.
One of his particularly insightful columns was one he wrote in late 2002 before the 2003 invasion of Iraq. He posed the question, is Iraq the way it is because Saddam is the way he is, or is Saddam the way he is because Iraq is the way it is? That's a brilliant question. It would have been helpful if the U.S. Administration had given much deeper thought to that question. Tom Friedman didn't know the answer to that question, but he was able to formulate it in a very interesting way.
More recently, when oil prices plunged in 2014, Tom Friedman wrote a very interesting piece on the correlation between the price of oil and political instability in petro states like Venezuela or Iran. He also talked about the role of the oil price collapse in the 1980s and the collapse of the Soviet Union. He's written a lot of interesting things, and he's written his book, The Lexus and the Olive Tree. It synthesizes globalization arguments with arguments about our cultural religious groundedness in specific places and the tension between those forces. He's written a lot of interesting stuff. He's a good storyteller. He can go from micro to macro and macro to micro really fast and seemingly seamlessly. He's very good at this. By contrast, Bill Flack has no track record of writing interesting things like this.
If you were to use Danny's attribution substitution heuristic—if you were to think in system one rather than system two mode about the problem—you might be inclined to slip into thinking, “Does Tom Friedman make a better forecaster? l don't really know, but I do know that he's got a lot higher status and has a lot more clout at the Council on Foreign Relations. He sold a lot more books.”
With the attribution substitution heuristic, you take a hard question like, is Tom a better forecaster? and you seamlessly substitute an easier question you can answer, and then you act as though the answer to the easier question is also an answer to the harder question. A lot of this can occur automatically, this kind of substitution. People do find it somewhat vexing to be asked questions that are unresolvable. There is this irritable reaching for certainty as one poet famously once put it. Of course, the right answer to the question, is Tom Friedman a better forecaster? is, nobody knows. But it's easy to get snookered by the attribution substitution heuristic.
There are some interesting counterarguments, and one of them is, “I still think the rational answer is Tom Friedman. I don't know what Tom Friedman's forecasting record is, but I do know that he has high status. And I do know that he's a skilled writer. I'm going to make an epistemic bet that these skills—the status and the writing skills—are positive, at least positively correlated with forecasting skill.” You could argue that.
It turns out though, and we know this from the IARPA tournament that Barb and I worked on for a number of years now, we also knew this from my earlier forecasting work as well, that the correlation between your ability to tell a good explanatory story and your forecasting accuracy is rather weak. It's not as strong an argument as you might think. Even if it is positive, it's not all that strong. There's a very powerful countervailing reason for believing that Bill Flack is a better forecaster, and that is because Bill Flack is a scientifically-documented, officially-certified IARPA tournament superforecaster. He did a great job assigning probability estimates to hundreds of questions posed over four years in the IARPA forecasting tournament, a superb performance. This is with neutral umpires, no room for fudging, this is objective scoring.
It's quite possible that Bill Flack is a better forecaster. I guess it brings us to what I see as a core paradox and that is, why is it that we know so much about Bill Flack's forecasting record and so little about Tom Friedman's? Why is it that most of the time we don't even know that we don't know that, and we don't even seem to care? Is that a satisfactory intellectual state of affairs? Is that a good way to be conducting high stakes policy debates, by relying on proxies like social status, the ability to tell a good story in determining who has the most impact on the policy debates?
If you read Tom Friedman's columns carefully, you'll see that he does make a lot of implicit predictions. He warned us, for example, early in the Clinton Administration right after the collapse of the Soviet Union that expanding NATO eastward could trigger a nasty Russian nationalist backlash. He's warned us about a number of things and uses the language of could or may—various things could or might happen. When you ask people what do "could" or "might" mean in isolation, they mean anything from about .1 probability to about .85 probability. They have a vast range of possible meanings. This means that it's virtually impossible to assess the empirical track record of Tom Friedman, and Tom Friedman is by no means alone. It's not at all usual for pundits to make extremely forceful claims about violent nationalist backlashes or impending regime collapses in this or that place, but to riddle it with vague verbiage quantifiers of uncertainty that could mean anything from .1 to .9.
It is as though high status pundits have learned a valuable survival skill, and that survival skill is they've mastered the art of appearing to go out on a limb without actually going out on a limb. They say dramatic things but there are vague verbiage quantifiers connected to the dramatic things. It sounds as though they're saying something very compelling and riveting. There's a scenario that's been conjured up in your mind of something either very good or very bad. It's vivid, easily imaginable.
It turns out, on close inspection they're not really saying that's going to happen. They're not specifying the conditions, or a time frame, or likelihood, so there's no way of assessing accuracy. You could say these pundits are just doing what a rational pundit would do because they know that they live in a somewhat stochastic world. They know that it's a world that frequently is going to throw off surprises at them, so to maintain their credibility with their community of co-believers they need to be vague. It's an essential survival skill. There is some considerable truth to that, and forecasting tournaments are a very different way of proceeding. Forecasting tournaments require people to attach explicit probabilities to well-defined outcomes in well-defined time frames so you can keep score.
These are very different ways of doing business. There is the traditional status hierarchy, and then there is the forecasting tournament. We say that forecasting tournaments are a disruptive technology because they have the potential to destabilize stale status hierarchies that are dominated by people who are good at telling explanatory stories after the fact, but aren't very good at predicting.
Brand: Phil, you invited some of these pundits to participate in the tournaments. What's their response?
Tetlock: We have indeed. Dan Gardner insisted that we do that and the response was very unenthusiastic. There was a small number of people who were willing to participate if they could be totally anonymous, but 90 percent-plus turned it down.
Brand: In interesting ways, or obvious ways? How much did they engage the problem?
Tetlock: Dan was fielding that correspondence, so I don't know. I didn't go through it in detail, but my sense is that a large fraction of them didn't even bother to respond and that another fraction offered somewhat polite but dismissive responses: "I'm sorry, I don't have the time." Interestingly, some of them offered a defense that is wrongheaded, and that is saying, "I don't really make predictions. That's not what I do. I'm not in the prediction business."
Brand: Did any of them besides David Brooks ever refer to your work in their own columns?
Tetlock: Yes. I don't want to talk about the specific people we invited or didn't invite. This work has been written up by a number of pretty high profile journalists and I have yet to see a negative review of the work. They have not been hostile toward the work, although that may change.
Brand: Nevertheless, it would be a large commitment of time to be in this—to answer these 400 or 500 questions.
Tetlock: Right. Well, you don't have to answer them all. You could get reasonable accuracy feedback if you were, over the course of a year or so, to answer 50.
Levi: All of the participants were volunteers? They weren't paid?
Tetlock: The description of how the forecasting tournament worked begins on slide fifteen starting, "Clearing the Conceptual Underbrush" the things you need to work out in order to do a forecasting tournament.

It's not as though the U.S. intelligence community exists in a world in which they are not held accountable for the judgments they make. It's the type of accountability. It's capricious. It's designed to induce shame if they get something big wrong, where getting something big wrong can be defined very expansively. Did the intelligence community miss 9/11? Well, they did create a memorandum that went to Condi Rice a few months before saying bin Laden is planning to attack the United States. That didn't say they were going to smash airliners into buildings in the Pentagon and New York City, but it did offer a warning of sorts. The intelligence community, for better or for worse, was held responsible for missing 9/11; that would be a false negative judgment. They were subsequently held responsible for overestimating the likelihood of weapons of mass destruction in Iraq; that's a false positive error.
One of the things about learning in Washington, D.C. and the intelligence community is if you're going to make a mistake, make sure you don't make the last mistake. If you make the mistake of missing something, missing a threat, make sure you don't miss another one. And if you make the mistake of having a false positive on a threat, make sure you don't make another false positive right away. Show, at least, that you're responsive to the political blame game calculus. We use the term “accountability ping pong,” that the intelligence community in some sense is whacked back and forth from making one error to the other. That is a form of learning, I suppose, in a very simple sense, but it's not the kind of learning that we're aspiring to achieve in the IARPA forecasting tournament. We're trying to improve our hit rate without simultaneously degrading our resistance to false positives.
Hillis: But it's also presumably true that making correct predictions is only part of what the intelligence community is there for. It's also there for coming up with stories that support whatever the decision is.
Tetlock: Yes, storytelling is indeed arguably the basis on which analysts are ultimately promoted or stay stagnant.
Axelrod: But there's also real evidence.
Tetlock: The intelligence community would be offended a little bit by what you said, Danny, because they see themselves as objective. They see themselves in principle as speaking truth to power. They're not there in a justification role.
Axelrod: Except for at the very top.
Tetlock: Except for the very top, right, who are political appointees.
Brooks: I feel a bit bad for Tom Friedman here. When you isolate things down to the sorts of questions on the last page here, which are all very well formed questions, that's one thing. But there's an alternate angle that the sort of things that Tom Friedman is doing is finding out what the questions are, and that he is living in a world where the opponents are doing the same sort of thing.
Is North Korea asking these crisp questions, or are they telling stories themselves? It's a much more complex dynamic. In my own world right now, I am besieged by people asking me a question, which I refuse to answer, and they get very angry at me for refusing to answer it because other people keep answering it. The question is, in what year will we have human level equivalent intelligence in computers? I say, “It's an ill-formed question.” They say, "But everyone answers it." But they shouldn't answer it because it's ill-formed.
Tetlock: The IARPA questions, of course, are not ill-formed in that sense because they pass the clairvoyance test. The clairvoyance test means that if the question is so well-framed that if you handed it to a genuine clairvoyant who could see perfectly into the future, the clairvoyant could look into the future, say thumbs up or thumbs down, without needing to come back to you for some ex post facto re-specification of what the question was. The problem you're having there is a question that fails the clairvoyance test, but I couldn't agree more with the sentiment you're expressing about Tom Friedman as a creative question generator.
A healthy intellectual tournament ecosystem requires people who are creative question generators as much as it does people who are skillful at generating accurate probability estimates. Some of the examples I gave you earlier—about petro state instability, or is Iraq the way it is because Saddam is the way he is or vice versa—those are smart questions. They're not questions that are quite ready for forecasting tournament application because they don't pass the clairvoyance test yet, but they're moving in that direction.
One of the most valuable collaborations that could be facilitated—and if this were a partial outcome of this gathering, I would consider it enormously successful—would be creating a framework for encouraging the Tom Friedmans of the world to play as question generators in forecasting tournaments, and agreeing that if questions resolve in a certain way within a certain time period, they would at least make some marginal adjustments to their beliefs.
Tom Friedman is a cautious supporter of the Iranian nuclear agreement right now. You could imagine posing a series of resolvable questions in the next twelve to twenty-four months about how the Iranian nuclear agreement unfolds that would cause either skeptics of the agreement or proponents of the agreement to change their minds somewhat. What does "change their minds" mean? Well, it doesn't mean going from yes to no. It might mean going from, “I think there was a .85 chance that the Iranians are not going to develop a nuclear weapon in secret, or they're not going to cheat in this way or that way on the agreement”—moving from .85 to .6, or to .75.
Among the best forecasters in the IARPA tournament believe change tends to be quite granular. They think that Hillary Clinton has a 60 percent chance of being the next President of the United States today, and then some information comes out from the State Department Inspector General about Hillary's emails and her possible culpability for her email policy: “Okay, I think I'm going to move it down to .58 now.” That's the sort of thing superforecasters do, and the cumulative result is that their probability scores, as defined in these handouts here and in the book, are much better. The gaps between their probability judgments and reality are smaller where your dummy code reality is 0 or 1, depending on whether the event didn't occur or did occur.
Lee: I doubt that Tom Friedman is thinking this way, but one reason to waffle a little bit is you're telling a story about some topic of wide interest, but to make a forecast for that there is some Bayesian process or some set of conditional probabilities where some of those nodes might be 50-50, and then it becomes, depending on how those earlier events turn out, you might have very definitive forecasts for the final event of interest.
Tetlock: Right. I certainly agree that we're talking about complex causal networks that could, in principle, be representatives of Bayesian inference diagrams. That's right. Some of the question clusters we have been developing in the IARPA tournament are moving in that direction. In the IARPA tournament to date, what we have done is we've asked conditional questions: If U.S. policy goes in toward A or B, how likely is a given consequence?
This allows us to assess the accuracy in the world in which one or the other policies is implemented. Let's say policy A is chosen, we know what happens. Interestingly, we don't know what would have happened if we had done policy B; that's in the realm of counterfactual. This is one of the great limitations in our ability to learn to become better calibrated in an historical environment because history doesn't offer control groups. Everything is counterfactual. In policy debates, we have this pretty perverse situation in which people routinely make up the data. They routinely invent convenient counterfactual control groups that make the policies they prefer look good.
It's even possible to take a policy like, say, the invasion of Iraq, which almost everybody has bailed on, but you could construct a counterfactual that says, “Well, you know what? If you think things are bad now, you have no idea how bad they would have been if Saddam had stayed in power.” There were people who defended the Vietnam War or the Iraq War on those grounds even after most opinion had bailed out. But counterfactuals are a very interesting and integral part. At the third session of this series, we'll deal with counterfactual inference in policy debates.
Lee: Just to say I would be very interested in knowing if the Seahawks will win the next Super Bowl.
Tetlock: Fair enough. There are benchmarks out there, right? There must be Las Vegas bookies and so forth. There may be prediction markets. There are benchmarks that we could use to start out, make, engage our initial probability estimation process.
Part 2
Brand: The one thing I draw from your work and from Danny's is a sense that stories are always wrong. These narrative accounts that we give are not only always wrong, they're always misleading because they're so comforting and persuasive. We want to tell stories, we like to hear stories, and once we've heard the story, we now understand the situation and we're done. It's pathological, our love of stories in this sense of trying to be accurate about things that might happen, or trying to understand the levels of what's going to. In biology, we encounter this all the time. There are so many simplistic stories relating to evolution, and you look a little deeper and it just isn't that simple ever.
Tetlock: It's a common debate in the history of philosophy of science, how loosely or tightly coupled explanations and predictions are. And it's certainly possible in the history of science to identify situations in which we think we have pretty darn good explanations, but they don't give as much predictive power—plate tectonics, earthquakes, evolutionary biology. There certainly are situations where we think the explanations are preposterous, but they did a pretty good job of predicting—Babylonian, Ptolemaic astronomy—they did a pretty good job with celestial motions, but they had no idea that stars were thermonuclear reactors.
There are cases where they're loosely coupled, but I would not want to take the strong position that they're totally uncoupled. The strength of the coupling of explanation and prediction is going to vary from domain to domain. The key thing is that we're aware that they're not as tight. I guess the key caution that emerges from Danny's work and others' is that we're too prone to the default assumption that explanation and prediction are tightly coupled; therefore, a useful corrective is to emphasize situations where they're loosely coupled and we're going to wind up perhaps somewhere in the middle.
Hillis: There's another dimension to it, which is that the very act of taking evidence and using that to adjust your prediction demands a framework of explanation. You have an operative story that you think, “Okay, well, this is how Hillary is going to get elected.” If you look at the failure of the intelligence community in the case of WMD, it was a failure of storytelling, not so much a failure of evidence interpretation. Retrospectively, you could tell a story of Saddam deliberately pretending like he had weapons of mass destruction, there's a story about his generals lying to him; none of those stories were told beforehand.
Had those stories been told beforehand, the evidence could have been interpreted differently. The same evidence could have been interpreted differently. In fact, that's part of what I was saying about the job of the intelligence community in storytelling is providing the frameworks in which you can interpret evidence and make predictions.
Tetlock: Right, right.
Brand: So you want red team storytellers.
Hillis: Well, yes.
Tetlock: Part of the official operating procedure of the CIA and officials is to have that. In the case of Iraq WMD, that process broke down. You had the situation where the Director of the CIA did say to the President of the United States, "It's a slam-dunk, Mr. President."
Axelrod: It's a slam-dunk to convince the American public.
Tetlock: That's what George Tenet says.
Axelrod: That's right. Well, that's what he did say. We have records on that.
Tetlock: Well, that's not what everyone says. George Tenet thinks he was blamed by the White House unfairly. The White House leaked it out of context. But it is fair to say that, even to put slam-dunk aside, the U.S. intelligence community was sending out a very decisive affirmation that Iraq did have an active weapons of mass destruction program; that was manifestly true. If the U.S. intelligence community had institutionalized forecasting tournaments, you would have created an organizational culture in which they would be much more reticent about ever using the term slam-dunk, whether at the level of PR or at the level of actuality because slam-dunk means 100 percent. 100 percent means I'm willing to give you infinite odds. That's quite extraordinary.
Kahneman: Or at least promise to eat your hat.
Tetlock: There are some scoring systems in probability scoring that if you attach a probability of one to something and it doesn't happen, that is reputational death. That's infinite. The Brier score, which we talk about in the handout, is more lenient toward people who are extremely overconfident. You can eventually recover from an error like that, but it takes a while to do it, and it's an interesting question of how punitive you want to be. I would ask you to entertain the counterfactual that if they had institutionalized forecasting tournaments inside the IC when they were engaging in those deliberations, would they have been at least a little more reticent? I am inclined to think that counterfactual is correct.
How much more reticent would they have had to have been to have persuaded Congress not to go along? Congress was getting the message that it was a slam-dunk from the Administration, and that was being communicated to the U.N., it was being communicated elsewhere. If the IC had a formal mechanism like a forecasting tournament, and the probability emanating from that was more modest, I think virtually every intelligence agency pre-invasion did think that Saddam did have some kind of active weapons of mass destruction program.
I am not saying that the ex ante best probability estimate of Iraqi WMD pre-2003 wasn't anywhere near 0. It was probably over 50 percent. I don't think it was 100 percent, but it was somewhere between 50 and 100, maybe 75, 80. Bob Jervis, who does a lot of these postmortems with the intelligence community, I'm not sure exactly what Bob would say that probability would be. I think he would agree with the characterization that they went too far, that the brakes weren't working on the inference process. The brakes that were supposed to be there on the inference process weren't working.
Would a forecasting tournament have saved us a multitrillion dollar mistake that could have cost tens of thousands of lives? I don't know. I would say that if you have a tool that can increase the accuracy of probability estimates—by 30, 40, 50, 60 percent—as much as has been demonstrated in the IARPA tournaments, it's worth investing many millions of dollars even to reduce, to a small degree, the probability of multitrillion dollar mistakes. That's a straight expected value.
Sutherland: The probability is not on its own a decent basis for a decision for the simple reason that there are things like the precautionary principle which might mean that a 5 percent chance of Iraq possessing WMD might be sufficient to justify invasion.
Kahneman: Well, Cheney went further—any nonzero.
Tetlock: The Bush Administration would have been very unhappy with the intelligence community that offered a 1 percent probability of WMD; that's not politically saleable.
Sutherland: Interestingly, what was the point of the super gun if they didn't posses WMD? Why would you invest in this hugely expensive and complicated gun which they were trying to build only to deliver conventional ballistics?
Tetlock: They may have had some ultimate intention of restarting their chemical weapons program. Iraq was pretty resource-starved and they were being watched a lot and harassed a lot, and it was difficult for them to do very much.
Wallach: How do you deal with the reflexivity of predictions, particularly in things like financial markets where people believing that something is going to happen makes it happen?
Tetlock: Analysts sometimes raise this issue inside the intelligence community because when they say something is probable and they take it to the Defense Department, the Defense Department could make it less probable. There is the problem of predictions being self-negating. Were you thinking of self-negating in this context?
Wallach: I was thinking confirming.
Tetlock: It could go either way, and the correct approach to that is what IARPA has done, which is to pose these as conditional: If we do X or Y, how likely is this to happen? As opposed to simply asking a question about how likely is this to happen.
Wallach: I guess the problem I'm raising is that someone like Tom Friedman making an argument on behalf of some action we should take stands a material chance of actually increasing the odds of what he's saying may happen. There's a huge power disparity between the people who make predictions in the world and those who have more power can actualize some of the things they're predicting.
Tetlock: Right. Journalists have some degree of influence there, but obviously the people inside the government are much closer to the mechanisms of power, so the self-negating/self-fulfilling prophecy problem is more pronounced there. There is no perfect solution to this because of the counterfactual problem, and we don't know what would have happened if we had done the other thing. You can partly address the issue, where you think there is potential for a self-fulfilling or self-negating mechanism, asking people on U.S. policy going down A or B, how likely is this or that. We still have the counterfactual problem; we'll come back to that later. But I think it's a good start.
Brooks: Our lives have been completely affected by an example of this. I think Gordon Moore's law, which, if you read the original paper, was based on five data points, one of which was null and four were just over a two-year period. He wrote this curve, he extrapolated it for ten years, and then the industry said, “Ah, that's what's going to happen,” and everyone worked that straight line for the next thirty or forty years. It completely transformed their world. It was exactly an example of a prediction changing the outcome, because without that I don't think that Intel and all the other chipmakers would have known what to aim for. That told them what to aim for.
Tetlock: We're going to complicate things more rapidly than I thought we would, but that comes back to Danny Hillis' point about explanation and how intertwined explanation and prediction are. Imagine that people hadn't believed the Moore article, they thought it was pretty farfetched, and they didn't make this concerted effort. Maybe about 100 years later, someone discovers it and things take off. The scientific underpinnings of Moore's law would be correct, but it would be radically off on timing, right? That's a very interesting conundrum that we encounter, which is that some forecasters can be radically wrong in the short-term, but radically right in the long-term. You need mechanisms for factoring that possibility into your decision calculus if you're an organization relying on forecasting tournaments for probability inputs into decisions.
We have a number of examples of situations in which very opinionated people offer interesting defenses for the inaccuracy of their short-term predictions. They'll say, "Well, I predicted the Soviet Union would continue and it almost did and it would have, but for the fact that those idiot coup-plotters were too drunk." We call that the close-call counterfactual defense, and what I predicted almost happened. It didn't happen but it almost happened, so you should give me some credit for being almost right rather than derogating me for being wrong.
There is the off-on-timing defense, and sometimes the off-on-timing defense is pretty specious. George Soros famously said that the markets can stay liquid longer than you can stay solvent, when people complain about bubbles and so forth and mispricing. A particularly interesting example of this was in my 2005 book, which a CIA analyst was reading and wrote to me last year saying, "Professor Tetlock, does this make you change your mind about hedgehogs?"
Foxes know many things but a hedgehog knows one big thing. The hedgehogs come in many flavors in expert political judgment. There are free market hedgehogs, there are socialist hedgehogs, there are boomster hedgehogs, there are doomster hedgehogs. They come in a variety of ideological complexions. This particular hedgehog was an ethnonationalist hedgehog.
What do I mean by that? In the Daniel Patrick Moynihan sense, he thinks that the world is seething with these primordial ethnic national identifications and existing nation-states are going to be rupturing all over the place in the next 50, 60 years (he wrote it in 1980). Then things like Yugoslavia and Soviet Union and so forth happened, and the Moynihan view started to look quite prescient. This ethnonationalist hedgehog writing, offering some forecasts in 1992, anticipates that by 1997 there is going to be a war between Russia and the Ukraine. The Russians are particularly obsessed with Crimea, but they're also going to see some eastern provinces of the Ukraine where there is a somewhat pro-Russian population, and they're going to use oil and gas as a weapon, and they're going to do things to the Ukrainians that more or less happened in 2014.
We're seventeen years off. The hedgehog gets a terrible accuracy score in the five-year time frame between 1992 and 1997. What do you think of that? That is an interesting complication. That is something we can't sweep under the rug. We need to think more systematically about how short-term and long-term foresight are related to each other, and that is one of the major focuses of what I thought would be the second session where we would talk about the importance of the questions we ask.
Brockman: For this second session, I'd be interested in how your thinking about hedgehogs has changed since 2005.
Tetlock: My thinking has evolved since 2005; that’s certainly true. I like to think of forecasting tournaments as intellectual ecosystems that require different types of creatures existing and reciprocal patterns of interdependence. The foxes need hedgehogs. The hedgehogs are very useful sources of information and insights. The foxes are almost parasitic in some ways on hedgehogs; they use hedgehog ideas and they're eclectic and they often combine, "Yes, I'll take this from this hedgehog, and that from this one." Just as there is a complementarity between Tom and Bill, and question generation and answer generation, forecasting tournaments, there's a complementarity between hedgehog and fox forecasters. The foxes are the ones looking for the deep parsimonious covering laws that capture the underlying drivers of history. The foxes wonder whether history has any underlying drivers. It may just be, as one famous historian said, "History is just one damn thing after another." There's a tension there between those two views of history, and it's a productive dialectical tension. I would not wish it away.
Kahneman: Going back to the Obama story that you started with. I'm not sure whether improving probability estimates is going to make a difference so long as the decision-makers don't think that way. There is demand for perfect accuracy, I'm not sure how much demand there is for slightly improved accuracy. The culture of decision-making is, in part, very oddly affected by the existence of hindsight so that they live in a world in which people who read prospectively will be sure that any action that didn't work was a mistake. When you live in that world and you face hindsight as a reality—something that will happen to you—it's unclear what that does to your willingness to go on probability because that's not what's going to happen to you.
Tetlock: Well, I did say at the beginning that you're somewhat more than I am.
Axelrod: People in positions of power on average have been luckier than average. They've made a lot of choices like, along the way to becoming President, some of which were disputed by their best advisors, and they were right and their advisors were wrong. Their known batting average has a substantial regression to the mean, which they tend not to account for, so they think that they're better judges. And they have good evidence for it because they have been better judges.
Tetlock: That's a beautiful point.
Axelrod: Another thing is Obama saying it's 50-50 is likely to mean something different than 50 percent. It's likely to mean, we don't really know. For him, the question is, do I order an attack on this building? Of course, we know he did. You might say that he had some threshold of probability that he would choose to act, and he has basically decided that it's above that threshold and that when he said 50-50, he basically was trying to communicate that this is not settled and he's going to have to take responsibility for the choice. If you actually had to push him toward odds, he would probably agree that three-to-one is a good bet.
Kahneman: What would be required for effective policymaking would be for the decision-maker to formulate the threshold in terms of probability. That is, when the probability exceeds that much, we will move. That is nowhere inside in the culture that there is a probabilistic structure. For these things to work, this is what's going to be needed.
Axelrod: Of course, they don't want to say in advance that if you tell me it's more than 35 percent, I'll attack.
Kahneman: No, if I believe that it's more than 35 percent, I will attack.
Tetlock: This is a very useful exchange here. Just to come to what Bob says about what Barack Obama might have meant by 50-50, absolutely right that 50-50 means something different to ordinary people and ordinary discourse than it does to probability theorists.
Baruch Fischhoff, who was a former student of Danny’s, famous for his work on hindsight bias, to which we will talk in a moment, had started one of his papers many years ago with a cute quote from a jockey who said, “There are eight wonderful colts in this race and each of them has a 50-50 chance of winning.” That bears out what you're saying.
To go back to Danny's points—the more pessimistic outlook here—first, you're right, there is not a huge demand among decision-makers for internal forecasting tournaments. There is some demand for it now, but there is certainly no tsunami. You could argue that's because there is no effective demand for something that you don't know exists. If you don't think that it's possible to make more granular probability estimates, you're not going to be demanding them. The other point about hindsight bias is very real, but forecasting tournaments are in a way a partial antidote to hindsight bias because they provide a clear documented record of what the ex ante probabilities were, so they would reduce the potential for that kind of distortion. But it's certainly a tough persuasion job.
Hillis: Another thing that goes back to the first story is what a totally rational decision-maker would want would be more than the probability, they would also want a confidence interval. In some sense, that may be what the difference is between all your experts telling you different probabilities and all your experts telling you the same, that you're guessing from that confidence interval.
Tetlock: It's certainly possible in the IARPA tournament to provide confidence intervals. The IARPA tournament was set up as a horse race. There were five university-based research teams competing to generate as accurate probability estimates as possible, and they could use whatever trick in the book they could come up with to achieve that. Tournaments incentivize people to cross the usual academic boundaries. You might think the trick lies in the cognitive ability of forecasters. You might think it lies in some extremizing algorithm. You might think it lies in teaming. You might think it lies in training. You might think it lies in networking, all sorts of different social science, behavioral science, statistical perspectives were brought to bear, and certain things turned out to work better than others within the context of this tournament. But confidence intervals are certainly a plausible product.
Hillis: I'm saying if Obama was playing poker and he knew the odds were this, then he probably would make his decision on probability. That's a case where he believes in the probability. But this wasn't a situation in which he believed in the probabilities. He thought this was more like an intelligence life kind of thing.
Tetlock: I know what you're saying, and that comes back to the limits of probabilistic reasoning. He's saying it lies outside. Let's just talk about that for a second. Were there comparison classes he could have used to judge? Osama was hardly the first terrorist the U.S. was going after. There were many previous terrorism hunts. Osama was, of course, the big catch, but it wasn't as though there weren't many precedents for planning Navy Seal operations against suspected terrorists in Afghanistan and Pakistan. There was a substantial number of them. You could argue that there was a base rate or a comparison class that could inform, even if you were a devout frequentist and you don't like Bayesian subjectivist statistics, you could have constructed at least some kind of rough comparison class for that.
Jacquet: I'm interested in the issue of granularity that you brought up. Do you believe that 100 is the best number of units? You were mentioning in the book that a lot of people use the base ten, or maybe the five, 95 percent, but that the superforecasters will actually adjust within 1 percent, 93 percent chance. My question is, especially for ordinary people who may use just five units as very unlikely or not, do you have a sense of what would be the best? Do you think 100 is the best number of units?
Tetlock: Oh, heavens, I don't have a general answer to that question. The fact that the superforecasters in aggregate were able to make twenty plus distinctions along the probability scale is an interesting fact. I don't think they can do that for all questions. Some questions are more amenable to that than other questions are. I don't think there is a generic off-the-shelf answer about how many degrees of uncertainty is possible to distinguish.
The collective wisdom of superforecasters is going to be more granular than the wisdom of any individual superforecaster, as the collective wisdom of a prediction market would be more granular than any given market participant. There is heightened granularity along that dimension. But there is no single number. It's something you discover when you do forecasting tournaments. One of the interesting discoveries of this tournament is that it’s possible to be more granular than many psychologists thought it was possible to be. Many psychologists thought five to seven would probably be a plausible upper bound.
Kahneman: Is it true that there'll be much more granularity when you follow the changing probability of an event? The first time you get information, you're not granular, and then you get added information and you can evaluate the size of the adjustment, and that would make it very granular.
Tetlock: That's exactly what happens in the belief updating process. The superforecasters are very well-practiced, belief updaters. If I make an initial guesstimate that the likelihood of Hillary being the next President of the United States is 60 percent, and then we come across the State Department Inspector General thing, I say, "Hmm, well, that doesn't help, probably doesn't hurt that much given the information available. How much? Probably not very much. It would certainly go down a bit. 58." I wouldn't have been able to pick that out if I were just coming at the problem afresh right after that State Department report, but because I have this comparison point anchor, I'm adjusting off that.
That's also true, to take a very simple case where you're running out of time for an event to occur, and I say, "Well, I thought there was a 5 percent chance of more than five people dying in the East China Sea in the Sino-Japanese clash by the end of the year. Time is running out, so now it's 4, 3, 2, 1.” That's a simple mathematical decay function, absent any information about the events on the ground.
Brand: I find one problem with the constant adjustment with the probability in your forecast in that the most valuable forecast is the one that's both early and relatively right. The forecast that is the day before the event being relatively right is way less valuable than the one that was right a year-and-a-half-ago. Is there any weighting of being more probabilistically right early versus later?
Tetlock: Yes. You get a lot. You do a lot better if you're closer to the truth early on because it's a cumulative Brier score across time, so you definitely reward it. Are you rewarded enough? That's an interesting question. There are many ways to score the accuracy of probability judgments. You could give even greater weight to being accurate further off than the Brier score does. The Brier score gives a lot of weight, but you could give even more, or you could punish people even more for saying 1.0 and it doesn't happen, or 0 and it does happen, because you want to teach people not to use 0 and 1, because Bayesian belief updating breaks down.
Brand: I realize my failure here. I didn't really understand Brier score, and maybe this weekend I will, and always will.
Tetlock: You see these probability judgments over time. This is who’s going to be inaugurated as President of Russia. What you see is a group of forecasters who think it's going to be Putin right from the beginning of the launch of the question, and that was before Medvedev formally bowed out.
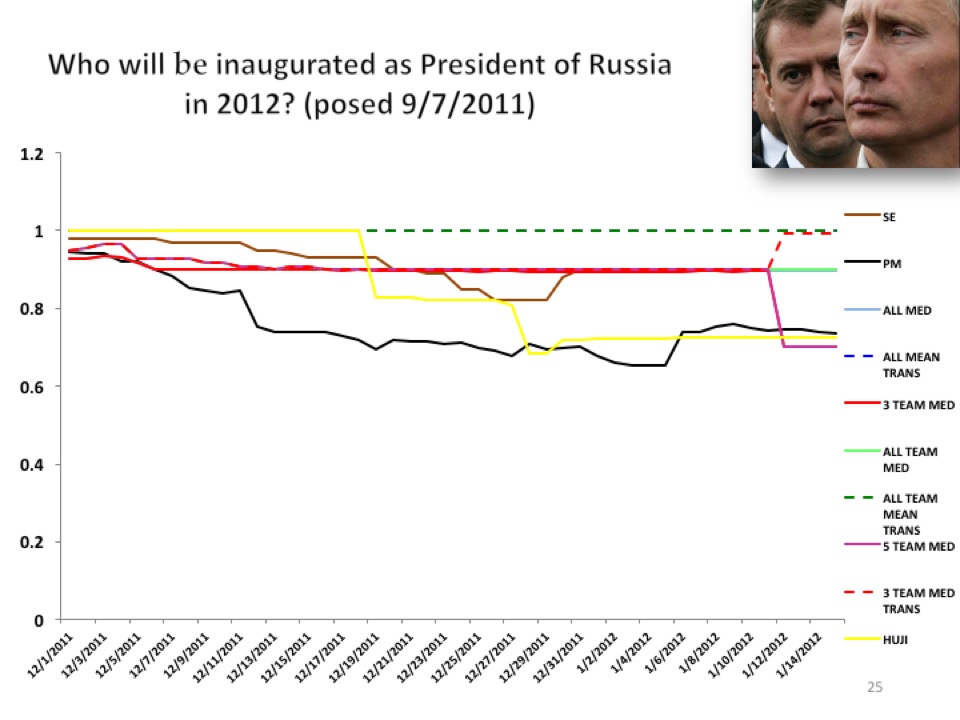
This is the probability of Putin being the next President of Russia in 2012, and the functions here essentially are different algorithms, different ways of capturing the wisdom of the crowd of our forecasters. These were the things we were submitting to IARPA. They were the basis for winning the tournament. You can see there are some people who are right around 99 percent all the way. That means when there are those big demonstrations in Moscow in early 2012, they looked at those demonstrations and they said, "Eh, we're not going to change our mind." Now, some of them did. Some of them did go down, but others, the "winners" viewed that as pseudo-diagnostic, not genuinely diagnostic information. There's another question lower down of relevance to the Eurozone was whether Mario Monti would vacate the office of Prime Minister of Italy before a certain target date. You can say that's all over the map; that was a wickedly difficult question.
There's another slide here that captures this in a very schematic artificial way—slide twenty-seven—the difference between pseudo-diagnostic and subtly diagnostic information.

The pseudo-diagnostic information would be, say, from the standpoint of those who think that Putin has an absolute lock on power in Russia, the fact that you had some large middle-class demonstrations in Moscow didn't move them very much at all. It did move the crowd, so you'd have the crowd, which would be the red line, taking a spike downward in response to the Moscow demonstrations. But the smart money, so to speak, would be pretty much monotonic toward 1.0.
That's where the smart money is discounting the information. Then there are other situations where information is subtly diagnostic where the smart money picks it up faster. People who had some doubts about whether Medvedev might continue as “President of Russia,” some of the more perceptive ones noted that Medvedev was not acting like a guy who was getting ready to campaign for office, that there had been a terrible plane crash, a number of famous Russian hockey players were killed, there was another sign of the terrible safety record of Russian transportation.
It was an opportunity for Medvedev to demagogue and be proactive and appear to be doing things the way a politician would want to do. He didn't, so it's like the Sherlock Holmes story of the dog that didn't bark. That would be more subtly diagnostic. The smart money moves on the subtle diagnostic, but the crowd does not.
The name of the game here is essentially to get to 1 fast when the event is going to happen, and to get toward 0 really fast when the event is not going to happen. There are some events such as the Monti case and a number of other questions in which the forecasters are quite violently non-monotonic, they go up and down because the situation is ambiguous and there are a lot of conflicting cues and everybody gets a bad Brier score. Well, almost everybody.
Kamangar: I’m thinking about Danny Hillis' point that maybe there is not a big dissonance necessarily between a story and a prediction. In some ways, a story is also an ideology, so I wonder is it possible that hedgehogs and foxes aren't really different species, it's more that hedgehogs can only hold one ideology in their heads at once while foxes can balance out lots of ideologies? And if so, have you looked at whether foxes are actually, through psychological mental testing, more capable of holding multiple thoughts at once, or is it just that they choose to do that while the hedgehogs have the capability but choose not to balance it out?
Tetlock: Where I talked about the hedgehog-fox tension, I threw in this quote from F. Scott Fitzgerald that the test of a first-class mind is the ability to hold two contradictory ideas in mind at the same time and retain the capacity to function. There is some truth to that. People vary in the degree to which they're tolerant of dissonance, tolerant of ambiguity. It is an important marker of creativity. It’s not always the case. Sometimes hedgehogs are spectacularly right. When we were talking over dinner last night, I mentioned to you that when you look at the people who have had the grand-slam home runs in forecasting tournaments tend more to go to the hedgehogs. The foxes get the better batting average. But if you're very, very tolerant of a lot of false positive predictions, you might want to go with the hedgehog.
Levi: Are there particular kinds of questions that the hedgehogs are better at?
Tetlock: There are so many different types, cognitive style maps in various ways on ideology, right? It's talking about cognitive style-ideology combinations, so what are the types of questions on which a hedgehog realist would do better? Or a hedgehog institutionalist? Hedgehog institutionalists, for example, have been very bullish on the Eurozone. They think that European politicians are so deeply committed to it that they're going to figure out a way to get through this mess. A lot of economists looked at the numbers on Greece and they say, “This is impossible. It’s just not going to work.” And the institutionalists say, “They'll make it work.” There may not be over-debt forgiveness, but they can have covert debt forgiveness, and there are ways of finessing these things. It's an interesting example though of where you have forecasters who have different theoretical orientations and perhaps different cognitive styles as well, coming at a forecasting problem in a quite different way.
I would say that Greece has lasted longer in the Eurozone than many economists thought it should or would, and if you want to go hedgehog-y, go to Martin Feldstein in 1990 or so when he said, "This is really stupid; you're going to have a common currency for these countries at these very different levels of economic development? Sounds like the United States and Mexico going in for a currency union. You guys have got to be kidding.”
Then, a few years later the Euro is at $1.50 to the dollar, and the Euro looks really strong and people are saying, “Well, so much for Feldstein.” Again, this is like the ethnonationalist hedgehog on the Ukraine or the Feldstein hedgehog on the Euro or Friedrich von Hayek in the 1930s thought that the Soviet Union was finished. The Soviet Union couldn't even exist, for that matter, because central planning was such an abominably bad idea. But the Soviet Union managed to limp along until 1991.
Linking short-term foresight and long-term foresight in tournaments is one of the great intellectual challenges here. I know Stewart and I talked about it yesterday and I continue to hold that view.
Brand: What we’re looking for is decade and century-scale foresight, along with the monthly and year-and-a-half-ly. It’s one of the things that is interesting that emerges that the hedgehogs sometimes are tapping into, in a sense deeper news or a deeper sense of the structure of what's driving things. Quite rightly, foxes are allergic to that because whenever they fall forth, their averages go down. You're creating more foxes by this whole process and that's good. You're converting some hedgehogs into foxes by this process.
Tetlock: At least making them a little more circumspect, yes.
Brand: People who go through these tournaments, as I understand it from Barbara, are themselves becoming more open-minded, more quantitative, less qualitative, less ideologically driven, and so on. The next level of challenge I would see would be to make better hedgehogs. Whatever that may mean, some kind of hybrid, a creature that is comfortable taking on longer-term retroactive and proactive understanding of structure. It’s all a hand-wave at this point, I don't know if I'm referring to anything.
Tetlock: Let me offer you an example of one of the ways in which tournaments might create better hedgehogs. In a forecasting tournament, you don't have the luxury that you have in academia of saying, "That's not in my field." When Jeffrey Sachs was arguing for shock therapy and rapid privatization in the early post-Soviet economies of the early '90s, he had a lot of critics saying he's going too fast. Later on, he said, “Well, I was right about the economics of rapid privatization, but there needed to be a legal system.” He needed more institutions.
But it was said almost as an afterthought as a way of saying, “I'm trying to look at economics. My economic analysis was sound, but I missed these other factors that are in another field: the law, institutions, corruption, culture. I missed that.”
Or Paul Krugman recently being interviewed by Fareed Zakaria about the recommendation he made to the Greek population about they should vote no on the loan referendum. Zakaria was asking him whether he had made a mistake, and Krugman said, "Yes, I think I did make a mistake. I think I overestimated the competence of the Greek government," meaning he didn't think they would be so dumb as not to have a backup plan if the European leaders didn't move. He thought they were bad game theorists, he didn't think they would be that bad. He thought they would have a very specific well-developed plan B that could be put on the table. They didn't.
Kahneman: It's a very funny sort of excuse. I made a mistake but they made a bigger one.
Tetlock: Like Sachs, the subtext of that is, “I'm a great economist, my economic analysis is fundamentally right. Okay, I got a little bit of trivial political psychology wrong. This person has a lower IQ than I previously thought. Big deal, I'm still wise. I still have good judgment.” What forecasting tournaments say to the forecasters is that you don't have this luxury of disciplinary compartmentalization anymore. You're going to have to be more integrated in your thinking. And of course, academia encourages specialization.
Brand: That's great, that's nice. That's a better hedgehog, I agree.
Christian: To this point of how do we create better hedgehogs, one of my questions is basically, Do we want to make hedgehogs themselves better at integrating other sources of information, or in some sense, do we want people to have this deep disciplinary expertise, and then we have some sort of aggregation mechanism for integrating it?
Tetlock: Do it statistically rather than inside one head? Do it statistically rather than cognitively?
Christian: Correct, right, right.
Tetlock: Yes. That's an interesting, that was an active debate in the IARPA tournament, yes, and it still hasn't been resolved.
Wallach: You talk about a group of predictors being like an ecosystem that overlay different ways of reasoning. Is it possible that you want different mixes of cognitive styles to deal with different problems? In other words, if I am trying to figure out what's going to happen with a mechanistic system like, will a bridge fail under certain stress tests or something, wouldn't a mix of structural engineers outpredict a mix of political scientists or something? And if, in the context of complex political future events, the people who are driving reality on the ground are themselves representative of a certain mix, wouldn't you want the prediction market to also mirror that mix? Does that make sense?
Tetlock: Yes. Not all forms of diversity are useful. The word "diversity" is useful insofar as it brings in a multidimensionality that maps onto the multidimensionality of the problem space. Yes. And no, I don't think the political scientist would do as well on the bridge.
Levi: I know they wouldn't. 100 percent probability.
